word2vec
一、总览
word2vec 是Mikolov在2013年在一系列paper中提出的一种训练词向量的方法,主要包含了两种模型. skip-gram 和cbrow.
主要涉及的paper 有如下:
Distributed Representations ofWords and Phrases and their Compositionality
Efficient Estimation of Word Representations in Vector Space
word2vec Explained: Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method
word2vec Parameter Learning Explained
说明:前面两篇论文“单词和短语的分布式表示及其组合性” 和“高效评估向量空间中的词表示” 这两篇论文都很笼统,给出的模型及其训练并不细致,以至于后面的两篇论文的作者提到”We found the description of the models in these papers to be somewhat cryptic and hard to follow” , 所以要想真正搞懂word2vec,就要结合这四篇论文一起看,最好能够结合cs224n assign2 ,以及cs224n 中的note1, note2 方能参透其中细节,get到真正有用的东西。
下图为word2vec的整体框架
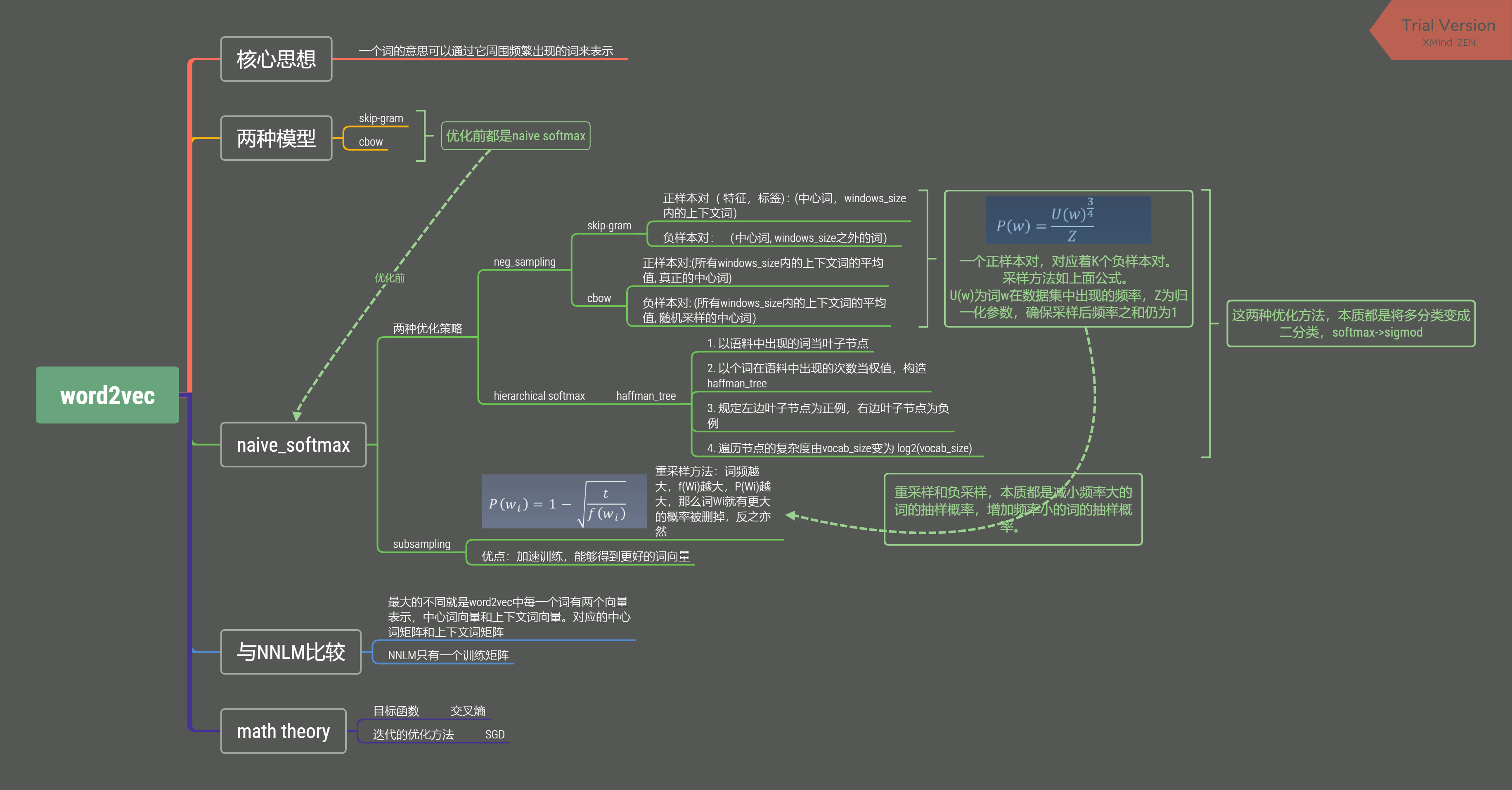
二、论文剖析
Abstract
We propose two novel model architectures for computing continuous vector representations of words from very large data sets. The quality of these representations is measured in a word similarity task, and the results are compared to the previously best performing techniques based on different types of neural networks. We observe large improvements in accuracy at much lower computational cost, i.e. it takes less than a day to learn high quality word vectors from a 1.6 billion words data set. Furthermore, we show that these vectors provide state-of-the-art performance on our test set for measuring syntactic and semantic word similarities.