TextRank: Bringing Order into Texts
1. 总览
TextRank 算法是PageRank算法在文本上的应用,它计算简单,而且不需要标注数据,可以用来提取文本的关键词,还可以用来提取文本摘要。要想彻底掌握TextRank, 必须要首先弄明白PageRank. TextRank 的关键在于构图,如何将图构建出来,只要图构建出来了,剩下的就是直接跟PageRank 一样,只要求出PageRank值,然后倒序获取top K 的顶点。以关键词提取为例来说明如何构图:先将文本按句子分开,针对每一个句子进行分词,词性标注,可以根据词性标注过滤掉一些无意义的词,然后将每一个词作为顶点,共现窗口内的词相当于有链接,直接做一条边。这样图就构建出来了。
TextRank工作得很好,因为它不仅依赖于文本单元(顶点)的本地上下文,而是从整个文本(图)中递归地考虑信息。(个人感觉怎么和Glove的思想这么像呢),本论文发表于2004年,相当早。
An important aspect of TextRank is that it does not require deep linguistic knowledge, nor domain or language specific annotated corpora, which makes it highly portable to other domains, genres, or languages.
TextRank一个主要的方面就是它不需要深入的语言知识,也不需要特定于领域或语言的注释语料库,这使得它可以高度移植到其他领域、类型或语言。
一点说明
因为是论文剖析,所以本文是针对论文的,从论文本本身出发的,针对论文中的关键章节,关键句子都一一记录,这样逐步形成论文的阅读和记录习惯,get到论文重点。另外论文本身描述的都是一种思想,虽然可以看到各种实验结果,但是如果不看代码,不自己动手实践,还是无法真正的掌握该算法。
2.论文剖析
Abstract
In this paper, we introduce TextRank – a graph-based ranking model for text processing, and show how this model can be successfully used in natural language applications. In particular, we propose two innovative unsupervised methods for keyword and sentence extraction, and show that the results obtained compare favorably with previously published results on established benchmarks.
1. Introduction
In short, a graph-based ranking algorithm is a way of deciding on the importance of a vertex within a graph, by taking into account global information recursively computed from the entire graph, rather than relying only on local vertex-specific information.
简而言之,基于图的排序算法是一种决定图中某个顶点重要性的方法,它考虑了从整个图中递归计算的全局信息,而不是只依赖于局部的顶点特定信息。
Applying a similar line of thinking to lexical or semantic graphs extracted from natural language documents, results in a graph-based ranking model that can be applied to a variety of natural language processing applications, where knowledge drawn from an entire text is used in making local ranking/selection decisions.
将类似的思维方式应用于从自然语言文档中提取的词汇图或语义图,将得到一个基于图的排序模型,该模型可应用于各种自然语言处理应用程序,其中从整个文中提取的知识用于作出本地排序/选择的决策。
Such text-oriented ranking methods can be applied to tasks ranging from automated extraction of keyphrases, to extractive summarization and word sense disambiguation (Mihalcea etal., 2004).
早在2004年,人们就发现,这种面向文本的排序方法可以应用在从关键词的自动提取到提取文本摘要和到词义消器的任务中。
In this paper, we introduce the TextRank graph-based ranking model for graphs extracted from natural language texts.
在这篇论文中,我们介绍了TextRank 一种基于图的排序模型用来从自然语言文本中提取图。
We investigate and evaluate the application of TextRank to two language processing tasks consisting of unsupervised keyword and sentence extraction, and show that the results obtained with TextRank are competitive with state-of-the-art systems developed in these areas.
我们研究和评估了,TextRank 在两种语言处理任务中的应用,这两种任务包括无监督关键字和句子提取,结果表明用TextRank 获得的结果与在这些领域中开发的最新系统具有竞争力。
2. TextRank model
Graph-based ranking algorithms are essentially a way of deciding the importance of a vertex within a graph, based on global information recursively drawn from the entire graph.
基于图的排序算法本质上是一种基于递归地从整个图中提取全局信息来决定图中某个顶点重要性的方法。
The basic idea implemented by a graph-based ranking model is that of “voting” or “recommendation”
基于图的排名模型的基本理念是“投票” 或”推荐”。
When one vertex links to another one, it is basically casting a vote for that other vertex. The higher the number of votes that are cast for a vertex, the higher the importance of the vertex.
当一个顶点连接到另外一个顶点时,它基本上是在为另一个节点投票。投给一个顶点的选票越多,这个顶点的重要性就越高。
Moreover, the importance of the vertex casting the vote determines how important the vote itself is, and this information is also taken into account by the ranking model. Hence, the score associated with a vertex is determined based on the votes that are cast for it, and the score of the vertices casting these votes.
此外,投票顶点的重要性决定了投票本身的重要性,排名模型也会考虑这些信息。因此与一个顶点关联的分数是基于投给它的票和投这些票的顶点的得分所决定。
Formally, let $G=(V, E) $ be a directed graph with with the set of vertices $V $ and the set of edges $E$, where $E$ is a subset of $V \times V$. For a given vertex $V_i$, let $In(V_i)$ be the set of vertices that point to it (predecessors), and let $Out(Vi)$ be the set of vertices that $Vi$ points to (successors).
The score of a vertex $Vi$ is defined as follows (Brin and Page, 1998):
where $d$ is a damping factor that can be set between 0 and 1, which has the role of integrating into the model the probability of jumping from a given vertex to another random vertex in the graph.
d 是一个(0,1)之间的阻尼系数, 它的作用是在图中将一个给定的顶点到一个随机顶点的概率整合到模型中去。
In the context of Web surfing, this graph-based ranking algorithm implements the “random surfer model”, where a user clicks on links at random with a probability $d$ , and jumps to a completely new page with probability $ 1 - d $ . The factor $d$ is usually set to 0.85 (Brin and Page, 1998), and this is the value we are also using in our implementation.
在网络冲浪的背景下,基于图的排名算法实现了“随机冲浪模型”, 在这个模型中,用户以概率d随机点击链接,以概率1-d调到一个全新的页面。因子d 通常设置为0.85, 在我们的实现中我们也将用这个值。
Starting from arbitrary values assigned to each node in the graph, the computation iterates until convergence below a given threshold is achieved 1. After running the algorithm, a score is associated with each vertex, which represents the “importance” of the vertex within the graph. Notice that the final values obtained after TextRank runs to completion are not affected by the choice of the initial value, only the number of iterations to convergence may be different.
首先对图中的每个节点随机赋值,迭代计算直到收敛低于给定阈值为止。运行算法后,每个顶点对应一个分数,表示图中该顶点的重要性。注意到 TextRank 运行结束后得到的最终结果不受初始值的影响,只是达到收敛的迭代次数可能不同。
It is important to notice that although the TextRank applications described in this paper rely on an algorithm derived from Google’s PageRank (Brin and Page, 1998), other graph-based ranking algorithms such as e.g. HITS (Kleinberg, 1999) or Positional Function (Herings et al., 2001) can be easily integrated into the TextRank model (Mihalcea, 2004).
值得注意的是,尽管本文中描述的TextRank应用程序依赖于一种源自谷歌的PageRank (Brin and Page, 1998)的算法,但其他基于图表的排序算法,例如HITS (Kleinberg, 1999)或位置函数(Herings et al., 2001)可以很容易地进行整合到TextRank模型(Mihalcea, 2004)。
For loosely connected graphs, with the number of edges proportional with the number of vertices, undirected graphs tend to have more gradual convergence curves.
Weighted Graph
In the context of Web surfing, it is unusual for a page to include multiple or partial links to another page, and hence the original PageRank definition for graph-based ranking is assuming unweighted graphs.
在互联网冲浪的背景下,一个页面到另一个页面之间有多个或特定的连接是不同寻常的,因此基于图的排名的原始的PageRank定义,是假设没有权重的图。
However, in our model the graphs are build from natural language texts, and may include multiple or partial links between the units (vertices) that are extracted from text.
然而,在我们的图模型是从自然语言文本中建立的,从文本中提取的单元(顶点)之间可以有多个或特定的连接。
It may be therefore useful to indicate and incorporate into the model the “strength” of the connection between two vertices $V_i$ and $V_j$ as a weight $W_{i j}$ added to the corresponding edge that connects the two vertices.
因此,指示并将两个顶点 $V_i$ 和 $V_j $ 之间连接的“强度”作为权重 $ W_{i j} $ 添加到连接两个顶点的对应边上可能是有用的。
Consequently, we introduce a new formula for graph-based ranking that takes into account edge weights when computing the score associated with a vertex in the graph. Notice that a similar formula can be defined to integrate vertex weights.
Text as a Graph
To enable the application of graph-based ranking algorithms to natural language texts, we have to build a graph that represents the text, and interconnects words or other text entities with meaningful relations.
为了能够在自然语言文本中应用基于图的排名算法,我们不得不建立一张图用来表示文本,并将单词和其他有意义的文本实体连接起来。
Depending on the application at hand, text units of various sizes and characteristics can be added as vertices in the graph, e.g. words, collocations, entire sentences, or others.
根据手头的应用程序,各种大小和特征的文本单元作为图中的顶点,例如:词,搭配词,整个句子或者其它成分。
Similarly, it is the application that dictates the type of relations that are used to draw connections between any two such vertices, e.g. lexical or semantic relations, contextual overlap, etc.
类似的,应用程序指定用于绘制任意两个顶点之间的连接的关系类型,例如词汇或语义关系,上下文重叠等。
Regardless of the type and characteristics of the elements added to the graph, the application of graphbased ranking algorithms to natural language texts consists of the following main steps:
无论添加到图中的元素的类型和特征如何,对自然语言文本使用基于图的排序算法的主要步骤如下:
- Identify text units that best define the task at hand, and add them as vertices in the graph.
确定最能定义手头任务的文本单元,并将它们作为顶点添加到图形中。
- Identify relations that connect such text units, and use these relations to draw edges between vertices in the graph. Edges can be directed or undirected, weighted or unweighted.
确定连接这些文本单元的关系并用这些关系画出图形中顶点之间的边。边可以是有向边或者无向边,有权重或者无权重。
-
Iterate the graph-based ranking algorithm until convergence.
迭代基于图的排名算法,直到收敛。
-
Sort vertices based on their final score. Use the values attached to each vertex for ranking/selection decisions.
根据最终分数对顶点进行排序。使用附加到每个顶点的值进行排名/选择决策。
In the following, we investigate and evaluate the application of TextRank to two natural language processing tasks involving ranking of text units:
接下来,我们将研究和评估TextRank 在两类涉及文本单元排名的自然语言处理任务中的应用。
(1) A keyword extraction task, consisting of the selection of keyphrases representative for a given text;
关键词提取任务包括对给定文本选择关键短语表示
(2) A sentence extraction task, consisting of the identification of the most “important” sentences in a text, which can be used to build extractive summaries.
句子提取任务包括确定一个文本中最重要的句子,它可以用来做提取摘要。
3. Keyword Extraction
The task of a keyword extraction application is to automatically identify in a text a set of terms that best describe the document.
关键字提取应用程序的任务是自动在文本中识别最能描述文档的一组术语。
Such keywords may constitute useful entries for building an automatic index for a document collection, can be used to classify a text, or may serve as a concise summary for a given document.
此类关键字可能构成有用的条目,用于为文档集合建立自动索引,可以用于对文本进行分类,或者可以用作给定文档的简要摘要。
Moreover, a system for automatic identification of important terms in a text can be used for the problem of terminology extraction, and construction of domain-specific dictionaries.
除此之外,一个能够自动识别文本中的关键术语的的系统可以用于术语提取问题和特殊领域字典的构建。
In this section, we report on our experiments in keyword extraction using TextRank, and show that the graph-based ranking model outperforms the best published results in this problem.
Similar to (Hulth, 2003), we are evaluating our algorithm on keyword extraction from abstracts, mainly for the purpose of allowing for a direct comparison with the results she reports with her keyphrase extraction system. Notice that the size of the text is not a limitation imposed by our system, and similar results are expected with TextRank applied on full-texts.
TextRank for Keyword Extraction
The expected end result for this application is a set of words or phrases that are representative for a given natural language text.
The units to be ranked are therefore sequences of one or more lexical units extracted from text, and these represent the vertices that are added to the text graph.
Any relation that can be defined between two lexical units is a potentially useful connection (edge) that can be added between two such vertices.
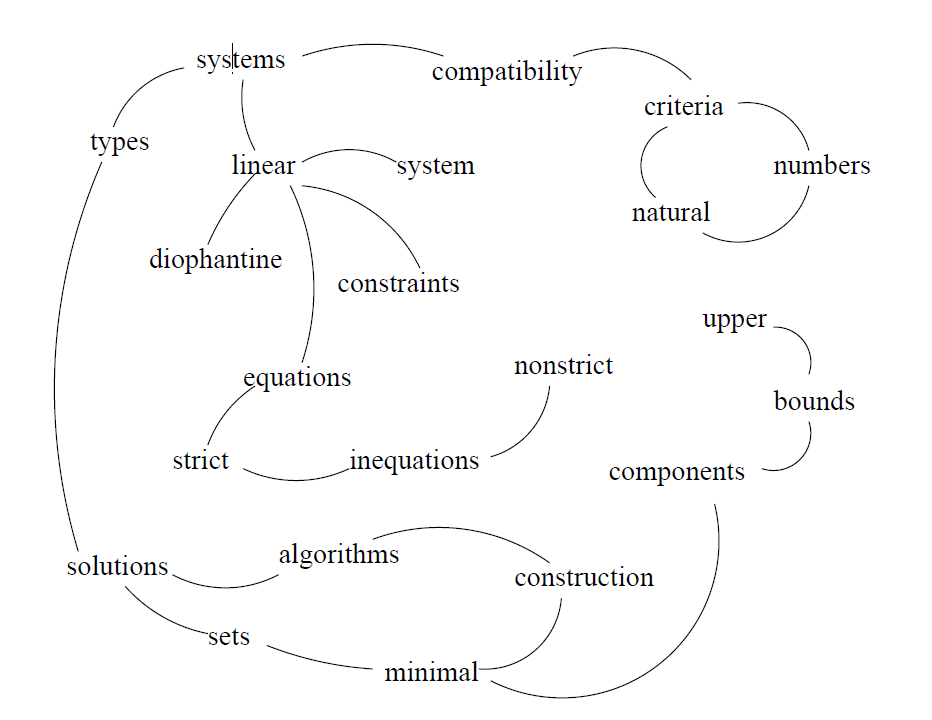
下面非常关键,顶点和边到底是怎么建立起来的。
We are using a co-occurrence relation, controlled by the distance between word occurrences: two vertices are connected if their corresponding lexical units co-occur within a window of maximum $N$ words, where $N$ can be set anywhere from 2 to 10 words.
共现窗口大小N 从2到10。
我们使用的是共现关系,由单词出现之间的距离控制:两个顶点相连如果它们对应的词汇单元在最大窗口N个词内同时出现,其中N可以设置为2到10个词。
Co-occurrence links express relations between syntactic elements, and similar to the semantic links found useful for the task of word sense disambiguation (Mihalcea et al., 2004), they represent cohesion indicators for a given text.
共现连接表达了句法要素之间的关系,与用于词义消歧任务的语义链接类似(Mihalcea et al., 2004),它们代表了给定文本的内聚性指标。
The vertices added to the graph can be restricted with syntactic filters, which select only lexical units of a certain part of speech. One can for instance consider only nouns and verbs for addition to the graph, and consequently draw potential edges based only on relations that can be established between nouns and verbs. We experimented with various syntactic filters, including: all open class words, nouns and verbs only, etc., with best results observed for nouns and adjectives only, as detailed in section 3.2.
The TextRank keyword extraction algorithm is fully unsupervised, and proceeds as follows.
TextRank 关键词提取算法是完全的无监督,过程如下:
First,the text is tokenized, and annotated with part of speech tags – a preprocessing step required to enable the application of syntactic filters.
1.首先对文本进行标记,并且用词性标注进行注释,这是实现应用语法过滤器所需的预处理步骤。
To avoid excessive growth of the graph size by adding all possible combinations of sequences consisting of more than one lexical unit (ngrams), we consider only single words as candidates for addition to the graph, with multi-word keywords being eventually reconstructed in the post-processing phase.
为了避免图的大小过度增长,通过添加所有可能的由多个词汇单位(ngrams)组成的序列组合,我们只考虑单个单词作为候选添加到图中,最终在后处理阶段重建多词关键字。
Next, all lexical units that pass the syntactic filter are added to the graph, and an edge is added between those lexical units that co-occur within a window of $N$ words.
2.接着,所有通过语法过滤器的词汇单位被添加到图中,并且在包含N个单词的窗口中同时出现的词汇单位之间添加一条边。
After the graph is constructed (undirected unweighted graph), the score associated with each vertex is set to an initial value of 1, and the ranking algorithm described in section 2 is run on the graph for several iterations until it converges – usually for 20-30 iterations, at a threshold of 0.0001.
3.图建立后,与每个顶点关联的分数被初始化为1, 排名算法运行很多次迭代直到收敛。 通常迭代20到30次,阈值设置为0.0001.
Once a final score is obtained for each vertex in the graph, vertices are sorted in reversed order of their score, and the top $T$ vertices in the ranking are retained for post-processing.
4.一旦获得了图中每个顶点的最终得分,顶点将按照其得分的相反顺序排序,并且保留排名中最顶端的顶点进行后处理。
While $T$ may be set to any fixed value, usually ranging from 5 to 20 keywords (e.g. (Turney, 1999) limits the number of keywords extracted with his GenEx system to five), we are using a more flexible approach, which decides the number of keywords based on the size of the text. For the data used in our experiments, which consists of relatively short abstracts, $T$ is set to a third of the number of vertices in the graph.
During post-processing, all lexical units selected as potential keywords by the TextRank algorithm are marked in the text, and sequences of adjacent keywords are collapsed into a multi-word keyword.
在后处理过程中,将TextRank算法选择的所有潜在关键字的词汇单位标记在文本中,并将相邻的关键字序列折叠成一个多词关键字。
For instance, in the text Matlab code for plotting ambiguity functions, if both Matlab and code are selected as potential keywords by TextRank, since they are adjacent, they are collapsed into one single keyword Matlab code.
例如,在绘制模糊函数的文本Matlab代码中,如果Matlab和代码都被TextRank选择为潜在的关键字,因为它们是相邻的,那么它们将被折叠成一个关键字Matlab代码。
Discussion
Regardless of the direction chosen for the arcs, results obtained with directed graphs are worse than results obtained with undirected graphs, which suggests that despite a natural flow in running text, there is no natural “direction” that can be established between co-occurring words.
不管为圆弧选择哪个方向,使用有向图获得的结果都比无向图获得的结果差,这表明尽管运行文本自然流动,但是在同现词之间无法建立自然的“方向” 。
Overall, our TextRank system leads to an Fmeasure higher than any of the previously proposed systems. Notice that TextRank is completely unsupervised, and unlike other supervised systems, it relies exclusively on information drawn from the text itself, which makes it easily portable to other text collections, domains, and languages.
4. Sentence Extraction
The other TextRank application that we investigate consists of sentence extraction for automatic summarization.
In a way, the problem of sentence extraction can be regarded as similar to keyword extraction, since both applications aim at identifying sequences that are more “representative” for the given text.
In keyword extraction, the candidate text units consist of words or phrases, whereas in sentence extraction, we deal with entire sentences.
TextRank turns out to be well suited for this type of applications, since it allows for a ranking over text units that is recursively computed based on information drawn from the entire text.
TextRank非常适合这种类型的应用程序,因为它允许根据从整个文本中提取的信息递归计算对文本单元的排序。
TextRank for Sentence Extraction
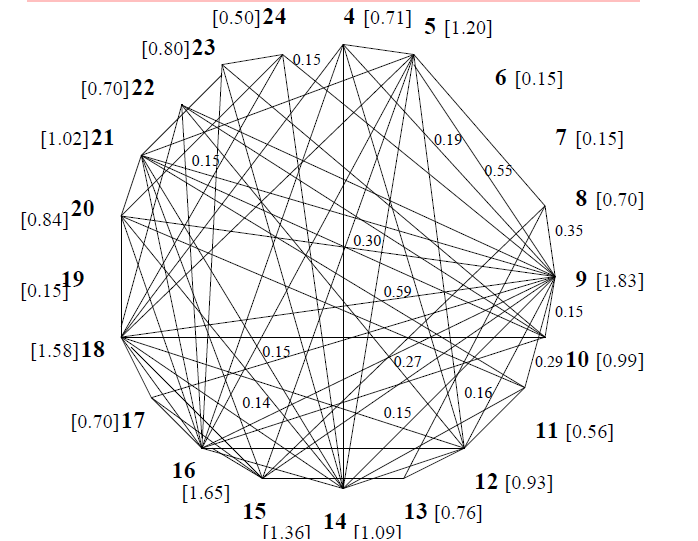
To apply TextRank, we first need to build a graph associated with the text, where the graph vertices are representative for the units to be ranked. For the task of sentence extraction, the goal is to rank entire sentences, and therefore a vertex is added to the graph for each sentence in the text.
要应用TextRank,我们首先需要构建一个与文本关联的图形,其中图形的顶点是 代表要排名的单位。对于句子提取的任务,目标是对整个句子进行排名,因此,为文本中的每个句子在图上添加了一个顶点。
The co-occurrence relation used for keyword extraction cannot be applied here, since the text units in consideration are significantly larger than one or few words, and “co-occurrence” is not a meaningful relation for such large contexts.
两个句子之间的关系的相似性通过内容重叠来进行测试。
Instead, we are defining a different relation, which determines a connection between two sentences if there is a “similarity” relation between them, where “similarity” is measured as a function of their content overlap.
Such a relation between two sentences can be seen as a process of “recommendation”: a sentence that addresses certain concepts in a text, gives the reader a “recommendation” to refer to other sentences in the text that address the same concepts, and therefore a link can be drawn between any two such sentences that share common content.
两个句子之间的这种关系可以看作是“推荐”的过程:一个句子针对文本中的某些概念,为读者提供“推荐”以引用文本中针对相同概念的其他句子,因此可以在共享共同内容的任何两个这样的句子之间绘制链接。
The overlap of two sentences can be determined simply as the number of common tokens between the lexical representations of the two sentences, or it can be run through syntactic filters, which only count words of a certain syntactic category, e.g. all open class words, nouns and verbs, etc.
可以简单地将两个句子的重叠确定为两个句子的词法表示之间的公共标记数,或者可以通过仅过滤特定句法类别(例如,英语)的单词的句法过滤器来运行这两个句子例如所有公开课单词,名词和动词等。
Moreover, to avoid promoting long sentences, we are using a normalization factor, and divide the content overlap of two sentences with the length of each sentence.
此外,为了避免提长句子,我们使用归一化因子,将两个句子的重叠内容除以每个句子的长度。
Formally, given two sentences $S_i$ and $S_j$ with a sentence being represented by the set of $N_i$ words that appear in the sentence: $S_{i}=w_{1}^{i}, w_{2}^{i}, \ldots, w_{N_{i}}^{i}$ , the similarity of $S_i$ and $ S_j $ is defined as :
Other sentence similarity measures, such as string kernels, cosine similarity, longest common subsequence,etc. are also possible, and we are currently evaluating their impact on the summarization performance.
The resulting graph is highly connected, with a weight associated with each edge, indicating the strength of the connections established between various sentence pairs in the text. The text is therefore represented as a weighted graph, and consequently we are using the weighted graph-based ranking formula introduced in Section 2.2.
After the ranking algorithm is run on the graph, sentences are sorted in reversed order of their score, and the top ranked sentences are selected for inclusion in the summary.
在图上运行排序算法后,将句子按其得分的相反顺序排序,然后选择排名最高的句子以将其包括在摘要中。
The sentences with the highest rank are selected for inclusion in the abstract.
Discussion
TextRank succeeds in identifying the most important sentences in a text based on information exclusively drawn from the text itself. Unlike other supervised systems, which attempt to learn what makes a good summary by training on collections of summaries built for other articles, TextRank is fully unsupervised, and relies only on the given text to derive an extractive summary, which represents a summarization model closer to what humans are doing when producing an abstract for a given document.
Notice that TextRank goes beyond the sentence “connectivity” in a text.
请注意,TextRank不仅仅是句子文本中的“连通性”
Another important aspect of TextRank is that it gives a ranking over all sentences in a text – which means that it can be easily adapted to extracting very short summaries (sentence), or longer more explicative summaries, consisting of more than 100 words.
Finally, another advantage of TextRank over previously proposed methods for building extractive summaries is the fact that it does not require training corpora, which makes it easily adaptable to other languages or domains.
5. Why TextRank Works
Intuitively, TextRank works well because it does not only rely on the local context of a text unit (vertex), but rather it takes into account information recursively drawn from the entire text (graph).
直观地说,TextRank工作得很好,因为它不仅依赖于文本单元(顶点)的本地上下文,而是从整个文本(图)中递归地考虑信息。(个人感觉怎么和Glove的思想这么像呢)
Through the graphs it builds on texts, TextRank identifies connections between various entities in a text, and implements the concept of recommendation.
通过它的迭代机制,TextRank超越了简单的图形连通性,它还能够根据文本所链接的其他文本单元的“重要性”来对文本单元进行评分。
A text unit recommends other related text units, and the strength of the recommendation is recursively computed based on the importance of the units making the recommendation.
一个文本单元推荐其他相关文本单元,推荐的强度是递归的根据作出推荐的单元的重要性计算出来的。
For instance, in the keyphrase extraction application, co-occurring words recommend each other as important, and it is the common context that enables the identification of connections between words in text.
例如,在关键字提取应用程序中,同时出现的单词相互推荐,并且公共上下文使识别文本中单词之间的联系成为可能。
In the process of identifying important sentences in a text, a sentence recommends another sentence that addresses similar concepts as being useful for the overall understanding of the text.
在识别文本中重要句子的过程中,一个句子会推荐另一个具有类似概念的句子,这样有助于对文本的整体理解。
The sentences that are highly recommended by other sentences in the text are likely to be more informative for the given text, and will be therefore given a higher score.
文本中被其他句子高度推荐的句子对于给定的文本来说可能更有信息量,因此得分会更高。
Through its iterative mechanism, TextRank goes beyond simple graph connectivity, and it is able to score text units based also on the “importance” of other text units they link to.
通过其迭代机制,TextRank超越了简单的图形连通性,而且它能够做到基于文本单元链接到的其他文本单元的“重要性”对文本单元进行评分。
The text units selected by TextRank for a given application are the ones most recommended by related text units in the text, with preference given to the recommendations made by most influential ones, i.e. the ones that are in turn highly recommended by other related units.
由TextRank为给定应用程序选择的文本单元是文本中相关文本单元最推荐的文本单元,优先考虑最有影响力的文本单元的建议,即其他相关单元强烈推荐的文本单元。
The underlying hypothesis is that in a cohesive text fragment, related text units tend to form a “Web” of connections that approximates the model humans build about a given context in the process of discourse understanding.
潜在的假设是,在一个紧密的文本片段中,相关的文本单元倾向于形成连接的“网络”,该网络近似于人类在话语理解过程中围绕给定上下文构建的模型。
6. Conclusion
In this paper, we introduced TextRank – a graphbased ranking model for text processing, and show how it can be successfully used for natural language applications. In particular, we proposed and evaluated two innovative unsupervised approaches for keyword and sentence extraction, and showed that the accuracy achieved by TextRank in these applications is competitive with that of previously proposed state-of-the-art algorithms.
An important aspect of TextRank is that it does not require deep linguistic knowledge, nor domain or language specific annotated corpora, which makes it highly portable to other domains, genres, or languages.
TextRank一个主要的方面就是它不需要深入的语言知识,也不需要特定于领域或语言的注释语料库,这使得它可以高度移植到其他领域、类型或语言。