- 文本匹配任务概览
- 传统匹配模型
- 基于表示的模型
- SiameseNet – Signature Verification using a “Siamese” Time Delay Neural Network
- DSSM – Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
- CDSSM – A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval
- LSTM-DSSM – SEMANTICMODELLING WITHLONG-SHORT-TERMMEMORY FORINFORMATIONRETRIEVAL
- MV-DSSM – A Multi-View Deep Learning Approach for Cross Domain User Modeling in Recommendation Systems
- A Deep Architecture for Matching Short Texts
- Convolutional Neural Network Architectures for Matching Natural Language Sentences
- CNTN – Convolutional Neural Tensor Network
- Learning to Rank Short Text Pairs with Convolutional Deep Neural Networks
- 基于交互的模型
- 语义匹配
- MatchPyramid – Text Matching as Image Recognition
- Pairwise Word Interaction Modeling with Deep Neural Networksfor Semantic Similarity Measurement
- Sentence Similarity Learning by Lexical Decomposition and Composition
- BiMPM – Bilateral Multi-Perspective Matching for Natural Language Sentences
- aNMM: Ranking Short Answer Texts with Attention-BasedNeural Matching Model
- ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs
- MIX: Multi-Channel Information Crossing for Text Matching
- DIIN:Natural Language Inference over Interaction Space
- QANet - Extending Neural Question Answering with Linguistic Input Features
- Match-SRNN:Match-SRNN Modeling the Recursive Matching Structure with Spatial RNN
- IARNN:Inner Attention based Recurrent Neural Networks for Answer Selection
- MwAN:Multiway Attention Networks for Modeling Sentence Pairs
- DecAtt – A Decomposable Attention Model for Natural Language Inference
- ESIM – Enhanced LSTM for Natural Language Inference
- A COMPARE-AGGREGATE MODEL FOR MATCHING TEXT SEQUENCES
- MCAN : Multi-Cast Attention Networks for Retrieval-based QuestionAnswering and Response Prediction
- HCRN:Hermitian Co-Attention Networks for Text Matching in Asymmetrical Domains
- HAR:A Hierarchical Attention Retrieval Model for Healthcare Question Answering
- DAM – Multi-Turn Response Selection for Chatbots with Deep Attention Matching Network
- HCAN - Bridging the Gap Between Relevance Matching and Semantic Matching for Short Text Similarity Modeling
- 相关性匹配
- DRMM: A Deep Relevance Matching Model for Ad-hoc Retrieval
- K-NRM: End-to-End Neural Ad-hoc Ranking with Kernel Pooling
- Conv-KRNM: Convolutional Neural Networks for Soft-Matching N-Grams in Ad-hoc Search
- PACRR: A Position-Aware Neural IR Model for Relevance Matching
- Co-PACRR: A Context-Aware Neural IR Model for Ad-hoc Retrieval
- 语义匹配
- 总结
- 关键词
- TODO
文本匹配任务概览
文本匹配是 NLP 领域最基础的任务之一,目标是找到与目标文本 Q 最相似的文本 D。 像信息检索的重排序(Information retrieval rank), 问答系统中(Quextion Answering)的候选答案的选取, 文本蕴含任务(textual entailment ),自然语言推理(Natural Language Inference) 等都可以看做文本匹配任务在各个领域的具体应用。
传统的模型如 TF-IDF, BM25 等通常会从字符串层面上计算 token 的匹配程度。 可是该方法无法处理 目标文本 Q 和 相似文本 D 间存在语义相关但文本并不匹配的情况 。为此研究人员先后提出了 LSA, LDA 等语义模型。随着深度学习的兴起,通过一系列非线性映射并结合 CNN,LSTM等结构提取文本深层次的语义特征低维向量表示取得了很好的效果。下面我们对近年来深度学习在文本匹配任务中的研究做一个概览。
从模型结构上可分为两类:
- 一类是纯基于表示的模型, 该类方法采用双塔式结构, 通过一些列深度网络将 Query 和 Doc 用低维向量表示出来, 而后采用 cosin , 欧氏距离等方式计算 Q 与 D 间的相似度。 典型的结构代表是 SiameseNet, DSSM, CDSSM, LSTM-DSSM, MV-DSSM 等。
- 另一类在获取Q 和 D 的表示后, 还加入了了二者的交互匹配策略, 该类方法认为纯基于表示的模型没有有效利用文本间的信息, 忽略了 Q 与 D 间的特征匹配,通过构建不同的特征匹配策略,模型可以获得更好的表现, 这里比较有代表性的就比较多,如 DecAtt, ESIM, BiMPM, ARC-I, MatchPyramid 等。
传统匹配模型
TF-IDF
TF-IDF 定义
TF-IDF 中,TF 是 Term Frequency 的缩写, IDF 是 Inverse Document Frequence 的缩写,因此 TF-IDF 即 词频-逆文档频率。它的公式定义为:
TF 表示词汇在文本中出现的频率。直觉上我们也知道,一个词在文档中出现的频率越高,那么这个词就越重要。
IDF 是包含该词汇文档频率的倒数再取对数。这意味着包含该词汇的文档越少,IDF 越大,这个词就越重要。最终 TF-IDF 表示为
即一个词在该文本中出现的次数越多,而在其他文本中出现很少时,则该词汇越能表示该文本的信息。
应用到文档检索中,就是根据 query 中的 term 在候选文档中的 TF-IDF 值求和作为候选文档的匹配得分。在早期的 Lucence 中,是直接把 TF-IDF 作为默认相似度来用的。在 Lucence 中,相似度计算公式做了一些调整:
其中 tf 是 关键字在文档中出现的次数。 后面的部分是文本长度归一化部分。
TF-IDF 为什么对逆文档频率取对数?
原因有二:
- 使用 Log 可以防止权值爆炸,如某个词只出现在一篇或者少数文档中,那么逆文档频率就会特别的大,从而使 TF 无效,使用 Log 可以减轻该影响。
- 对停用词(“的”,”是”)这种在每个文档都有的词,逆文档频率接近于1,又因为对这种词 TF 会很高,因此也会得到较高的 TF-IDF 分,这不符合我们的期望,但加上 Log 后,该部分接近0,符合我们的预期。
TF-IDF 为什么长这个样子?除了感性的解释外,有什么理论依据么?
传统的TF-IDF是自然语言搜索的一个基础理论,它符合信息论中的熵的计算原理,虽然作者在刚提出它时并不知道与信息熵有什么关系,但你观察IDF公式会发现,它与熵的公式是类似的。实际上IDF就是一个特定条件下关键词概率分布的交叉熵。
还有一种是基于先验的解释,可以看这篇文章,TF-IDF模型的概率解释
BM25
BM 是 Best Matching 的简写,它是基于 TF-IDF 进行改进了的算法。从上面 TF-IDF 的公式中可以看到,二者的乘积理论上可以是无限大的,BM25 对其进行了限制,使其收敛某一特定值。
BM25 设计的一个重要依据是:词频和相关性之间的关系是非线性的,也就是说,每个词对于文档的相关性分数都不会超过一个特定的阈值。当词出现的次数到达一定的阈值后,其影响就不在线性增加了,而这个阈值和文档本身有关。因此对于TF 部分,BM25 将原始公式替换为
其中 tf 表示单词在文档中的词频, k 是一个常量,用来限制 TF 值的增长极限, TF 极限被限制在 0 - k+1之间,在业务中理解为某一音速的影响强度不能是无限的,而是有一个最大值,这样才符合实际逻辑。在 Lucence 中 k被设置为 1.2。
除此之外, BM25 还引入了平局文档长度的概念,单个文档长度对相关性的影响力与它和平均长度的比值有关系。 因此BM25 的 TF 公式里还有另外另个参数 文档长度和平均长度的比值L 和 常数b, b 用来规定 L 对评分的影响有多大。因此最终评分为
上面这些都是 TF 部分,对于 TDF 部分,变化比较小:
BM25在传统TF-IDF的基础上增加了几个可调节的参数,使得它在应用上更佳灵活和强大,具有较高的实用性。
偏最小二乘法(PLS)
PLS 来源于统计中的回归技术,偏最小二乘的方法,将 query 和 doc 通过两个正交映射矩阵 和 映射到同一个空间后得到向量点积,然后通过最大化正样本和负样本的点积之差,使得映射后的latent space两者的距离尽可能靠近。为此匹配函数可以定义为:
匹配函数得到的结果作为匹配分数,优化目标是最大化正样本的匹配分数:
其中 是query 和 doc 的 click 数。这是一个非凸优化问题,但存在全局最优解,可以通过 SVD 进行求解。
Regularized Mapping to Latent Space
当数据量较大时,PLS很难学习,因 为需要求解时间复杂度较高的 SVD。吴等人提出了一种新的方法 称为regularized mapping to latent space(RMLS)来解决这个问题。具 体地说,它们用稀疏性假设代替PLS 公式中的正交性假设来构造RMLS。 这样,可以并行地进行优化,从而 使学习算法具有可扩展性。
RMLS 在空间表示、训练数据以及优化目标表示上都与 PLS 一致,区别在于转化矩阵 和 上,PLS模型的基本假设要求两个矩阵是正定的;而RMLS模型在此基础上加入了正则限制,整体优化目标下公式所示:
不能保证 RMLS 存在全局最优解。可以使用贪婪算法进行优化,即先固定 ,再优化 ,再固定,再优化 。
Supervised Semantic Indexing
SSI 和上面方法类似,它将潜空间模型写作:
令 ,则
SSI 尝试将 W 进行分解:
当 W = I 时,该模型退化为 VSM 模型,当 时,该模型和 PLS 与 RMLS 等价。
SSI 用点击日志得到偏好对作为训练数据,利用 hinge loss 作为损失,采用梯度下降进行优化。
Statistical Machine Translation
SMT 基于统计机器翻译的方法,在给定 doc 以及目标 query 的情况下,从 doc 到 query 的翻译过程。公式表达为
其中 h 时关于 q, d 的特征函数。整个求解过程看成是特征函数的 线性组合。
Word-base Translation Mode
WTM 把 doc 和 query 看成概率模型,即给定 doc,最大化当前 query 的概率。
其中 Q 和 D 是 query 和 doc 文本, q 和 w 表示 query 和 doc 对应的 term。将上述概率进行分解得到
其中 表示给定 doc 中词 w 的前提下, query 词 q 出现的概率,即二者的关联性,我们称之为 translation probability。这是一个概率模型,是要求的。
表示给定 文档 doc 的前提下,词 w 出现的概率,我们称之为 document language model,可以通过计算词 w 在文档中出现的次数除以文档 D 的总词数得到。
但上式存在一个问题,对于很多稀疏的 term,一旦出现某个概率为零,那连乘就变成 0 了。为了避免这个就需要做平滑。为此引入 background lm , 其中 C 表示整个 collection, 表示当前 query 的单词 q 再整个 collection 出现的次数。则平滑后的 WTM 模型为:
但上式还有问题,即孙在 self-translation 的问题,即 ,为此 可以引入 unsmoothed document lm 来解决
基于表示的模型
SiameseNet – Signature Verification using a “Siamese” Time Delay Neural Network
深度学习大佬 Yann LeCun 的文章, 论文目的是手写签字验证。网络结构如下图所示:
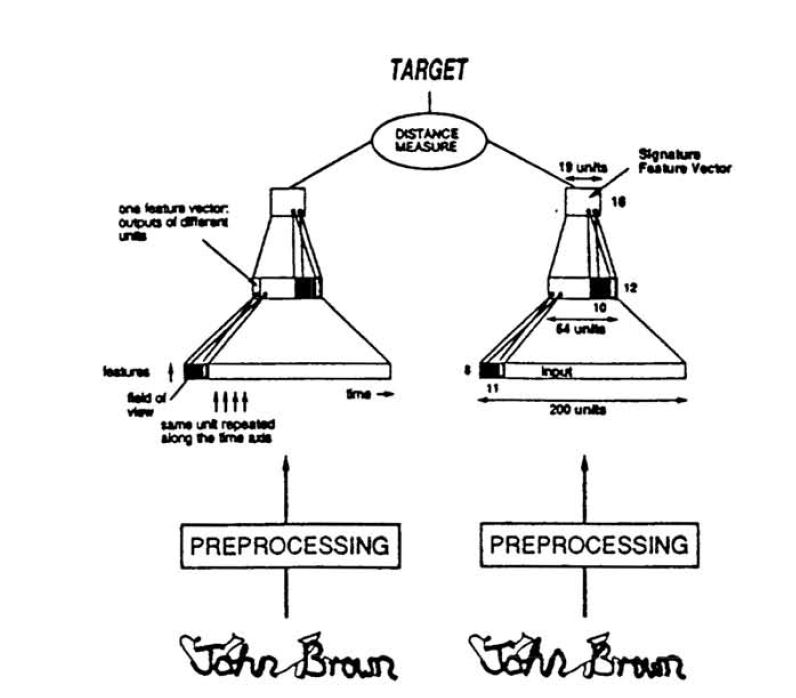
论文比较久远,图片比较糊。。。。我用文字表述一下, 其中我们只关注左右两个网络中的一个, 因为它们的参数是共享的。
- 首先输入是一个手写签名, 通过一系列预处理程序后得到对应的向量表示,就是标记 200 的那个(input 阶段)
- 该表示通过多层 CNN 提取特征, 采用均值池化( 特征表示阶段 )
- 通过下采样和均值操作得到低维表示(聚合阶段)
- 通过计算余弦得到两个向量间的相似度(相似度计算阶段)
这篇论文是很值得学习的, 虽然结构比较简单, 但很经典, 后面的大部分研究都是在该结构的基础上进行改进的。
至于损失函数, 常用的是对比损失函数(contrastive loss)、Hinge loss, 交叉熵损失函数等。对比损失函数的公式为
其中
是两个样本特征的欧氏距离。y 是两个样本是否匹配的标签。 margin 是人为设定的阈值。
DSSM – Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
DSSM 是工业界最常用的模型之一,来自微软,该模型结构简单,效果较好。后续也有很多跟进的改进, 如 CDSSM, LSTM-DSSM 等。
模型的流程如下图所示:
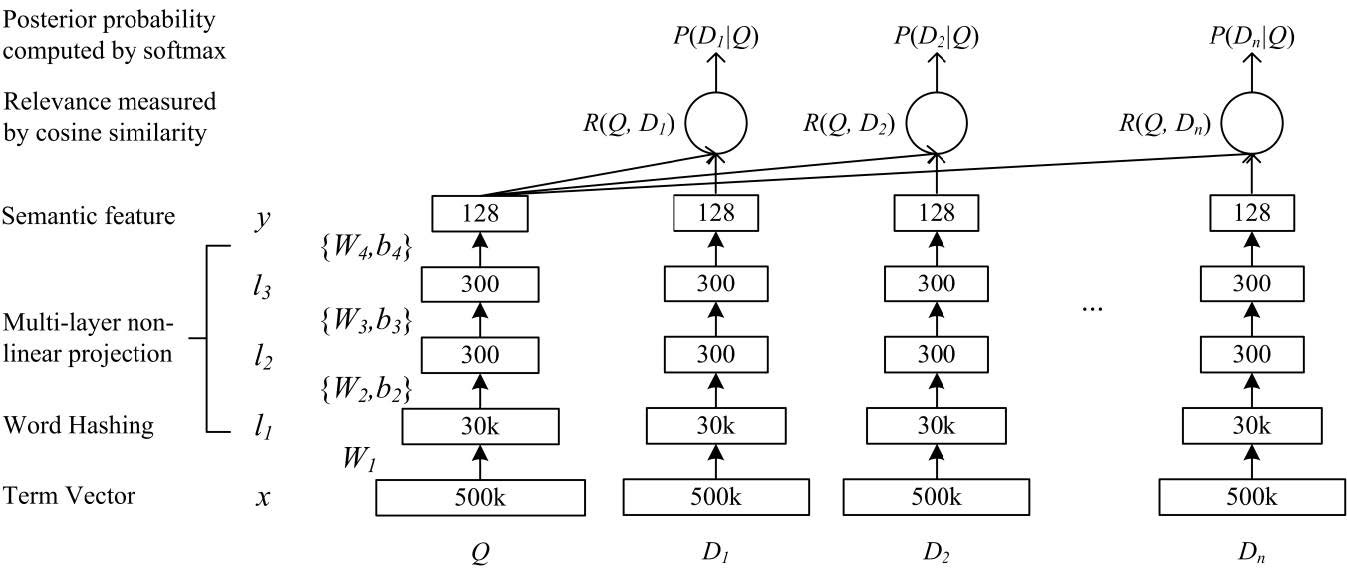
- DSSM 首先将输入通过 word hashing 进行编码(input)
- 执行非线性投影将查询 Q 和文档 D 映射到公共语义空间, 中间的 multi-layer 采用的是线性连接+ tanh 激活函数(特征表示+聚合)
- 计算 Q 和 D 对应语义表示之间的余弦相似度(相似度计算)
- 对相似度执行 softmax,得到归一化概率分布来表示Q 和 每个文档 D 的匹配程度
- 用 Clickthrough 数据训练(用户的检索 Q 和 4 个点击的文档 D 构成的数据集),训练目标是条件似然最大化
可以看出该模型遵循 SiameseNet 的四段式结构。这里说一下比较特殊的地方。 首先是 word hashing, 它的目的是解决大规模搜索中词汇表过大的问题。经统计,未采用 word hashing 前,词汇表的大小达到 500k。而经过 word hashing 后, 词汇表大小就变成 30 k 了。
word hashing 是基于 “字符 n-gram “的,以例子说明, 对于 输入 “word”, 我们对其加上开始和终止符号 “#word#”, 如果采用 3-gram 的话, 那么我们就会得到 “#wo”、”wor”、”ord”、”rd#” 四个部分。对于所有的输入都进行这样的拆分并统计就得到拆分后的词汇表,也就是 30k 的那个。 当我们输入一个词时, 首先我们对其进行这样的切分, 而后类似于 one-hot 那样, 在 30k 的词汇表内出现的位置标记为 1, 其余为 0. 这样我们就得到了该词的 multi-hot 表示。该方法的缺点是比较怕碰撞,这样效率就会降低, 不过作者统计了一下, 在 3-gram 的情况下碰撞概率只有 0.0044%(22/500,000)。几乎没有影响。
第二个特殊的地方是, DSSM 中 Q 和 不同的 D 对是共享参数的, 即 W1, W2, W3, W4 即用来处理Q,也用来处理D。
第三个点是优化目标, 对应的公式为
即只考虑了正例带来的损失, 负例不参与反向传播。
CDSSM – A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval
CDSSM(CLSM) 是对 DSSM 的改进版, 它将 DNN 换成 CNN, 更充分考虑语义上下文信息。模型整体结构和 DSSM 一样, 只不过是将 DNN 部分换成了 CNN, CNN 部分如下图所示:
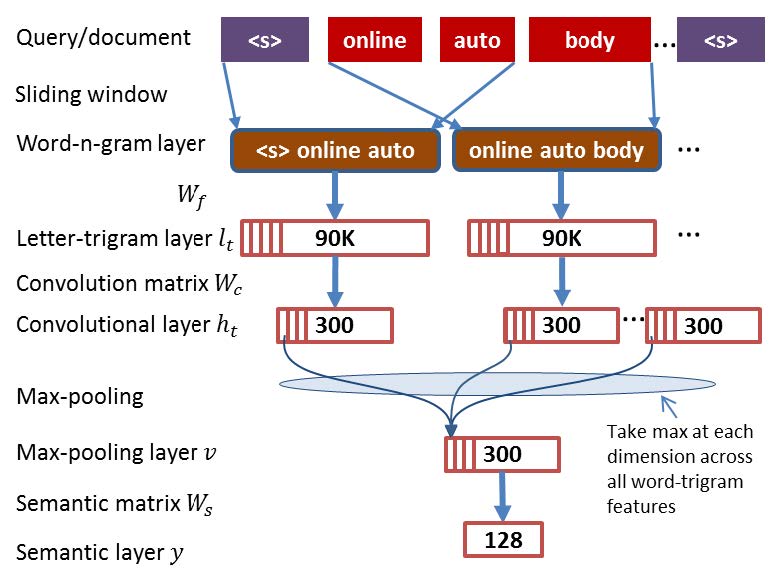
整体流程为:
- 输入的 Query 和 Document 是一系列词
- 采用窗口大小为3 , 步长为 1 的滑动窗口获得一系列的 tri-gram。
- 对于 tri-gram 内的每个词, 采用 word hashing 的方法得到对应的 multi-hot 表示, 而后将 3 个词对应的表示首尾连接在一起, 如 3 个 (1,30k) 的组成 (1, 90k) 的(input 层)
- 对该向量进行卷积、最大池化、tanh 激活等操作得到定长特征表示(特征表示)
- 利用线性映射, 得到低维语义表示(聚合操作)
- 通过 cosine 计算 Q 和 D 间的相似度, 后面的和 DSSM 一样了
LSTM-DSSM – SEMANTICMODELLING WITHLONG-SHORT-TERMMEMORY FORINFORMATIONRETRIEVAL
DSSM 的另一种改进, 第一次尝试在 信息检索(IR)中使用 LSTM,模型的创新点是将 DNN 替换成了 LSTM,用 LSTM 最终时间步的输出作为语义编码结果。模型结构如下图所示
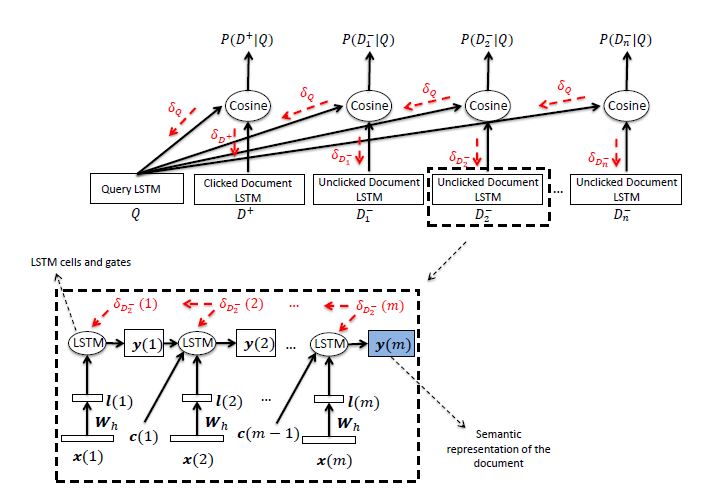
模型整体结构没什么细说的,需要注意的一个是这里的 LSTM 不是标准的, 而是添加了 C_{t-1} 的 peephole 连接去辅助计算各个门。如下图所示, 更进一步可以看LSTM 详解

用 LSTM 的好处是可以进一步考虑长时序相关的信息, 还可以减轻梯度消失等问题。
MV-DSSM – A Multi-View Deep Learning Approach for Cross Domain User Modeling in Recommendation Systems
该改进是为了更好的在推荐系统领域应用语义匹配方法,所谓 Multi-view 是指采用了多类数据,而非原始中只有 Q 和 D,是单一领域的, 可以看做 single-view,通过该改进模型就具备了多领域匹配能力。 另一个改进是 MV-DSSM 中各 view 的 DNN 的参数是独立的, 而原始 DSSM 模型的 DNN 参数是共享的, 独立参数可以有更好的效果。
A Deep Architecture for Matching Short Texts
该论文提出了一种新的深度架构,可以更有效地对来自异构域的两个对象之间的复杂匹配关系进行建模。更具 体地说,论文将此模型应用于自然语言的匹配任务,这种新的体系结构自然地结合了自然语言问题固有 的局部性和层次结构,因此大大改进了最新模型。
该模型的提出基于文本匹配过程的两个直觉:1)Localness,也即,两个语义相关的文本应该存在词级别的共现模式(co-ouccurence pattern of words);2)Hierarchy,也即,共现模式可能在不同的词抽象层次中出现。这种新架构能够 在匹配两个结构化对象 时显式捕获自然非线性 和分层结构。
模型实现时,并不是直接统计两段短文本是否有共现词,而是先用(Q, A)语料训练 LDA 主题模型,得到其 topic words,这些主题词被用来检测两个文本是否有共现词,例如,若文本 X 和文本 Y 都可以归类到某些主题词,则意味着它们可能存在语义相关性。而词抽象层次则体现在,每次指定不同的 topic 个数,训练一个 LDA 模型,最终会得到几个不同分辨率的主题模型,高分辨率模型的 topic words 通常更具体,低分辨率模型的 topic words 则相对抽象。在高分辨率层级无共现关系的文本,可能会在低分辨率层级存在更抽象的语义关联。不难看到,借助主题模型反映词的共现关系,可以避免短文本词稀疏带来的问题,且能得到出不同的抽象层级,是本文的创新点。
模型结构如下图所示:
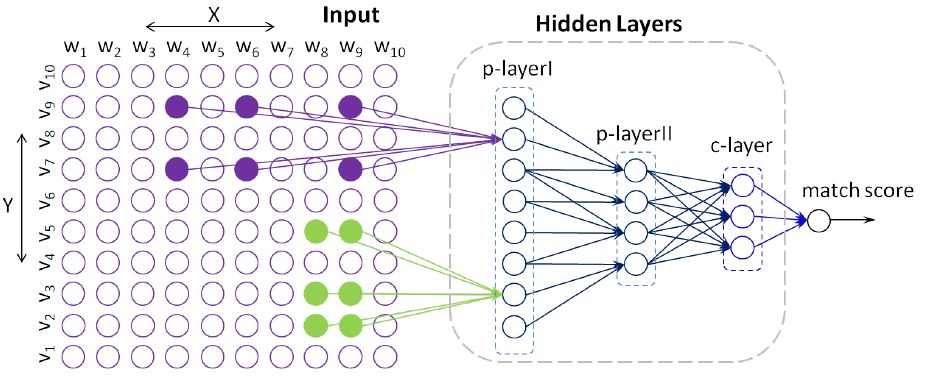
上图中左侧 Input 中,不同的颜色代表不同的 topic 抽象层级。模型的具体构建细节没细看,下面大体说一下。构建用于匹配的深度架构的 过程包括两个步骤。 首先, 我们使用双语主题模型定义 具有不同分辨率的并行文本 patches。 其次,我们构造描 述主题层次结构的分层有向 无环图(DAG),并在此基 础上进一步构造深度神经网 络的拓扑。
对于并行文本的主题模型构造,将并行文本中的单词简 单地放到一个联合文档 中,而每个单词都使用 不同的虚拟词汇域,以 免混淆。对于建模工 具,我们对所有训练数 据使用Gibbs抽样的潜 在Dirichlet分配 (LDA)。在低分辨率 的 L 个 topic 语料中进行 拟合。
至于匹配的结构构建共分为3 步。第一步先对输入词 (query 和 doc)的低概率 topic 进行裁剪,并将每个 topic 保留下来的 词定义为 patch p。第二步基于 patches,构建有向无环图(DAG) g,最后基于g,构建 patch induced 神经网络层。层之间的权值使用稀疏连接并通过反向传播进行学习。
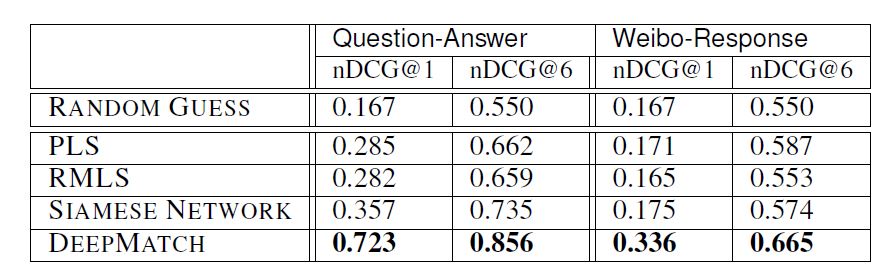
最终结果如下图所示,由于是比较早的工作,因此对比模型是 PLS 和 RMLS:
Convolutional Neural Network Architectures for Matching Natural Language Sentences
一个成功的匹配算法需要 对语言对象的内部结构以 及它们之间的交互进行充 分的建模。DSSM 只使用 非线性映射对 query 和 doc 序列进行编码,并且没有考虑 query 和 doc 间的交互作用。本论文针对这两个缺点,提取 ARC-I 和 ARC-II 两个模型。前者是基于表示的模型,和 CLSM 思想相同,都是用 CNN 去提取 Local 特征再聚合。后者是基于匹配函数得到匹配矩阵再用 CNN提取特征。所提出的模型不仅 能很好地描述句子的层次 结构及其分层组合和集 合,而且能捕捉到不同层 次上丰富的匹配模式。
ARC-I 的结构如下图所示:
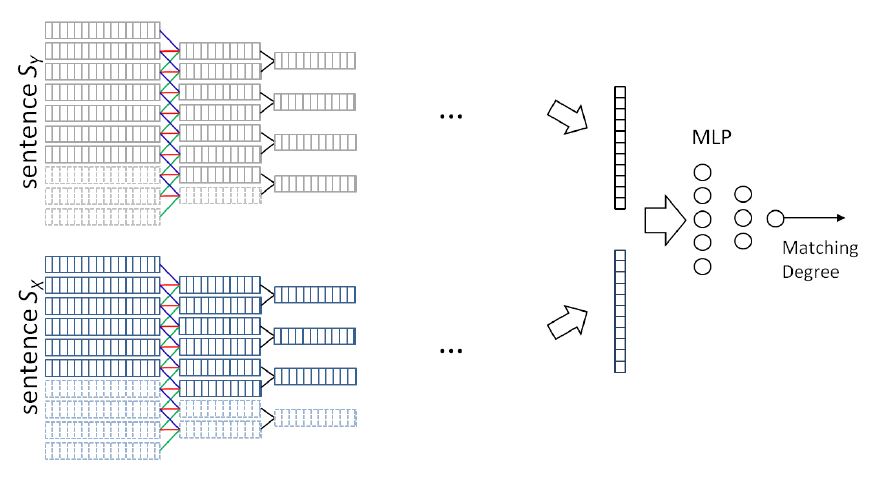
典型的 Siamese 结构,对于 query 和 doc 分别进行特征提取得到固定维度的向量,而后用 MLP 进行聚合和分类。因此重点是 CNN 怎么用的:
- 多层CNN 的堆叠:卷积 + pooling 堆叠
- 卷积操作采用窗口宽度为k1 的卷积核,初始输入时采用 0 填充到固定长度
- pooling 采用 宽度为 2 的 max-pooling, max-pooling 可以提取最重要的特征,进而得到 query 和 doc 的表示。
- 单层 CNN 可以捕捉相邻 Term 间得多种组合关系,即 local 的 n-gram 特征。比 DSSM 要强一些。
- 虽然多层 CNN 的堆叠通过感受野的扩张可以得一定的全局信息,但对于序列信息还是不敏感。对语义依赖强的任务效果一般。
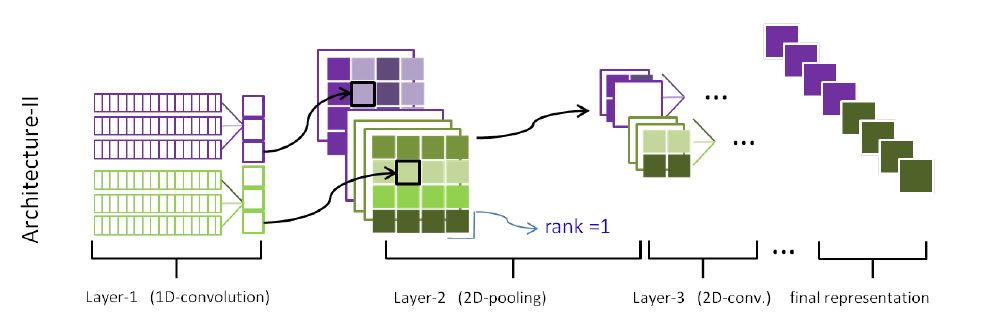
ARC-II 的网络结构如下图所示:
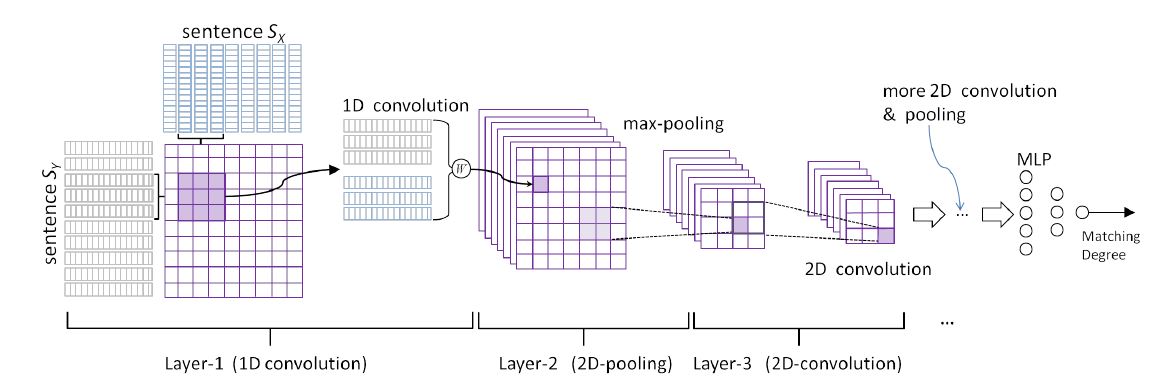
ARC-II 在一开始就引入了 query 和 doc 间的交互,构建一个矩阵,先用 1 维卷积作用,而后用多层二维卷积 + 池化进行作用,最终输入 MLP 进行分类。因此重点是 1 维卷积和 2 维卷积 + 池化如何做的:
- 先构建矩阵,假设 query 长度为 m,嵌入维度为 H, doc 长度为 n, 嵌入维度为 H 。则 矩阵中每个元素是 query 中的 第 i 个 词向量与 doc 中第 j 个词向量进行 concat 得到的向量。因此矩阵的维度是 [m, n, 2H] 。
- 用 1 维卷积进行扫描,宽度为 k1。通过这种方式即可以得到 query 和 doc 间的匹配关系,还保留了语义和位置信息。
- 对得到的结果用 2维 卷积进行处理,池化还是 宽度为 2 的池化。这一步就和图像那面处理多通道图片是一样的了。
- 其实 ARC-I 可以看做 ARC-II 的特殊情况。即中间的交互过程中二者没有交互,特殊的权值使它们在 MLP 前都独自流动,如下图所示:
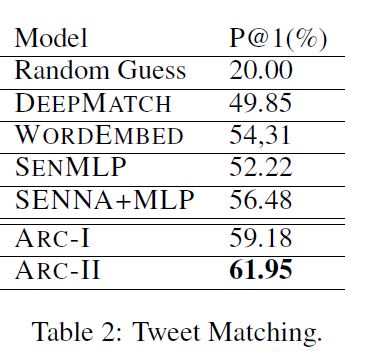
在推特匹配任务中, ARC-I 比以往的模型好很多, ARC-II 又比 ARC-I 好很多,说明 CNN 模块的有效性和 doc 与 query 交互的必要性。
CNTN – Convolutional Neural Tensor Network
论文用 CNN 进行编码,创新点是在聚合的时候用 Neural tensor network( NTN) 匹配, 得到匹配分数。网络结构如下图所示:
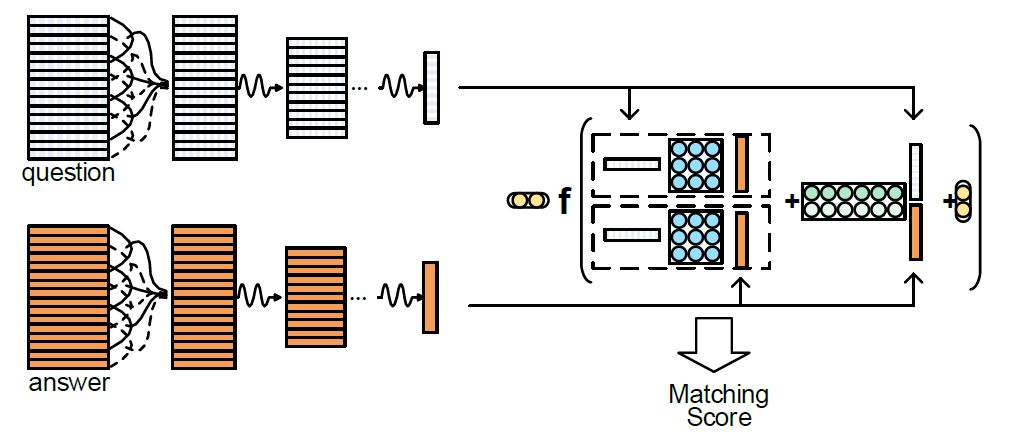
对于给定的 query 和 doc,先 embedding 得到对应的向量表示。而后用 CNN 得到对应的定长的向量 q 和 d。则 NTN(neural tensor network) 用公式表达如下:
其中第一项可以看做是 bilinear 计算相似性,第二项是 concat 计算相似性,和在 attention 里那些计算相似性方法一样,核心思想是用更多的网络参数来学习 q 和 d 的匹配分数,而不像 cosine 那样。 f 是一个非线性操作, u 是映射矩阵,都是可学习的。
Learning to Rank Short Text Pairs with Convolutional Deep Neural Networks
用 textCNN 提取语义特征, 而后采用相似度矩阵计算特征表示间的相似度。根据该相似度,再结合Q 和 D 的语义特征向量连接起来作为聚合表示。 最后通过 线性层和 softmax 进行分类。模型流程如下图所示
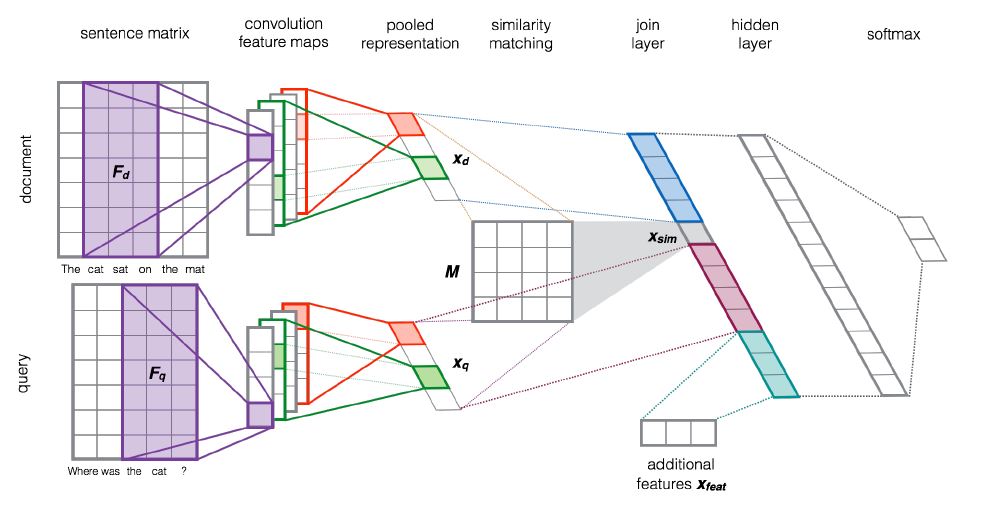
模型流程为:
- 输入一个文档 Q/D, 以 Q 为例, 它的长度为 $l_{q}$,其中每个词采用 word2vec 的嵌入向量表示,维度为 d。(input)
- 对输入进行卷积操作, 卷积核大小为(3, d),步长为1, 对于 pad 的问题, 作者认为, pad 后卷积核可以平等的对待边界部分的单词,同时对于长度小于卷积核大小的情况也能处理, 因此建议 pad。池化部分采用最大池化,作者认为平均池化时每部分都有贡献,正向信号会被负向信号抹平。而最大池化会突出正向信号, 但缺点是容易过拟合。该部分的输出为 $x_{q}$/$x_{d}$(特征表示)
- 使用 $x_{q}$、$x_{d}$ 计算相似度 , 该相似度得分是一个标量
- 将相似度得分和 $x_{q}$、$x_{d}$连接起来得到聚合的向量表示, 在该步骤还可以添加额外的特征 $x_{feat}$
- 通过线性层和 softmax 部分进行分类(相似度计算)
改论文相比于 CDSSM 有几个比较明显的改变。 首先改论文发表于 2015 年, 此时已经有 word2vec 等一系列较为成熟的 word embedding 方法, 因此没有采用 word hashing 方法。
另一方面, 卷积操作也采用我们现在比较熟悉的方式, 即卷积核是沿着时间序列扫描的, 深度为词向量维度 d。而 CDSSM 里是在 (1,90k) 的向量上扫描的, 个人认为这得益于 word2vec 的稠密向量表示。
还有该模型在一定程度上考虑了 Q 和 D 间的交互匹配, 也就是 这块,后续交互改进的一大重点就是挖掘Q 和 D 间的交互匹配。
最后一个变化是训练优化目标变成了交叉熵损失函数, L2 正则化。
基于交互的模型
除了考虑输入的表示外, 还利用各种 Q 和 D 间的交互匹配特征,尽可能的匹配二者间的不同粒度信息。
具体来说:
- 词级别匹配:两个文本间的单词匹配,包含字符相等匹配(down-down)和语义相等匹配(famous-popular)
- 短语级别匹配: 包含 n-gram 匹配和 n-term 匹配,n-gram指像 (down the ages 和 down the ages)的匹配, n-term 匹配是指像 (noodles and dumplings 和 dumplings and noodles) 的匹配。
- 句子级别的匹配: 由多个低层次的匹配构成
除此之外,还有词和短语间的匹配等等模式, 如何很好的发掘这种模式并利用起来是研究的重点之一。
根据匹配任务的特点,此处将匹配分为语义匹配和相关性匹配。
具体来说, 语义匹配有三个特点:
- 相似性匹配信号:与精确匹配信号相比,捕获单词、短语和句子之间的语义相似性/关联性是非常重要或关键的。例如,在释义识别中,需要识别两个句子是否用不同的表达方式表达相同的意思。在自动对话中,我们的目标是找到一个与前一个对话语义相关的恰当的应答,而这一应答之间可能没有任何共同的词或短语。
- 组合意义:由于语义匹配中的文本通常由具有语法结构的自然语言句子组成,因此基于这种语法结构使用句子的组合意义更为有利,而不是将它们视为一组/一系列单词。例如,在问答中,大多数问题都有清晰的语法结构,有助于识别反映问题内容的组成意义。
- 全局匹配要求:语义匹配通常将两段文本作为一个整体来推断它们之间的语义关系,从而产生全局匹配要求。这在一定程度上与大多数语义匹配文本的长度有限,主题范围集中有关。例如,如果两个句子的意思是相同的,那么这两个句子就被认为是释义,一个好的答案可以完全回答这个问题。
与此相反,ad hoc检索中的匹配主要是相关匹配,即识别文档是否与给定的查询相关。在这个任务中,查询通常是简短的,并且基于关键字,而文档的长度可能会有很大的变化,从几十个单词到几千个甚至几万个单词。为了估计查询和文档之间的相关性,相关性匹配主要关注以下三个因素:
- 精确匹配信号:尽管术语不匹配是ad hoc检索中的一个关键问题,并且已经用不同的语义相似度信号来解决,但是由于现代搜索引擎的索引和搜索范式,文档中术语与查询中术语的精确匹配仍然是adhoc检索中最重要的信号。例如,Fang和翟提出了语义项匹配约束,即精确匹配原始查询项对关联度的贡献不应小于多次匹配语义相关项。这也解释了为什么一些传统的检索模型,例如BM25,能够完全基于精确匹配信号而工作得相当好。
- 查询词重要度:由于在ad hoc检索中,查询词主要是基于关键字的短查询,没有复杂的语法结构,因此考虑词重要度是很重要的,而查询词之间的组合关系通常是操作搜索中的简单“与”关系。例如,在查询“比特币新闻”时,相关文档预计是关于“比特币”和“新闻”的,其中“比特币”一词比“新闻”更重要,因为描述“比特币”其他方面的文档比描述其他事物“新闻”的文档更相关。在文献中,已经有许多关于检索模型的正式研究表明了术语区分的重要性
- 不同的匹配要求:在ad hoc 检索中,相关文档可能很长,文献中关于文档长度的假设也不尽相同,导致匹配要求不同。具体地说, Verbosity Hypothesis 将长文档当做段文档看,覆盖范围相似,但单词较多。在这种情况下,如果我们假设整个文档有一个核心的主题,那么相关性匹配将是全局的。相反,Scope Hypothesis 假设一个长文档由许多不相关的短文档连接在一起。这样,关联匹配可以发生在相关文档的任何部分,并且我们不要求整个文档与查询相关。
接下来分别进行介绍。
语义匹配
MatchPyramid – Text Matching as Image Recognition
将Q 和 D 进行匹配得到 匹配矩阵(matching matrix),矩阵的每一个点表示 Qi 和 Dj 的相似度,相似度计算分别尝试用 indicator(0, 1), cosine 和 dot 三种。 而后将该矩阵看做一张图像,采用图像那面的卷积方法来处理它。通过卷积操作,模型可以捕获短语级别的交互并通过深层网络进行深层次的组合。 模型流程如下图所示
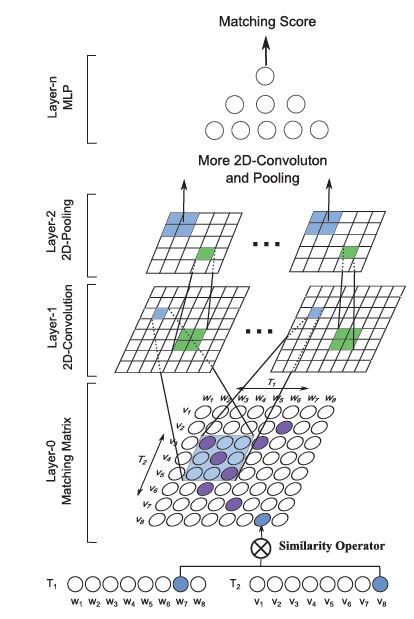
这里重点说一下从文本到 matching matrix 这步,给定 $Q = (w_{1}, w_{2}, \dots, w_{lq})$ 和文档 $D = (v_{1}, v_{2}, \dots, v_{ld})$,我们将会得到一个形状为 lq * ld 的矩阵M, 其中的每个元素 $M_{ij}$ 表示 $w_{i}$ 和 $v_{j}$ 计算相似度得到的值。
- Indicator 函数, 则当 $w_{i}$ 和 $v_{j}$ 一样时 为 1, 否则为 0.
- Cosine 函数,
- Dot product:
实验结果表明 点乘的效果最好。
Pairwise Word Interaction Modeling with Deep Neural Networksfor Semantic Similarity Measurement
该论文充分利用了 Q 和 D 间的相似匹配特征,构建了一个深度为 13 的匹配矩阵,而后加一层 mask, 该mask 会对重要的信号进行放大, 弱相似的缩小。通过上述方式得到 matching matrix, 而后采用 19 层的深度 CNN 进行特征提取得到特征表示,最终模型通过 2 个全连接层和softmax操作进行分类。改论文充分利用了两个文本之间的多种相似性模式,并以此作为后续 CNN 的输入, 不过个人感觉,这种完全采用相似矩阵作为后续输入的方式是否真的通用有效, 毕竟从文本到相似矩阵这步丢失了很多语义信息。
模型流程如下图所示
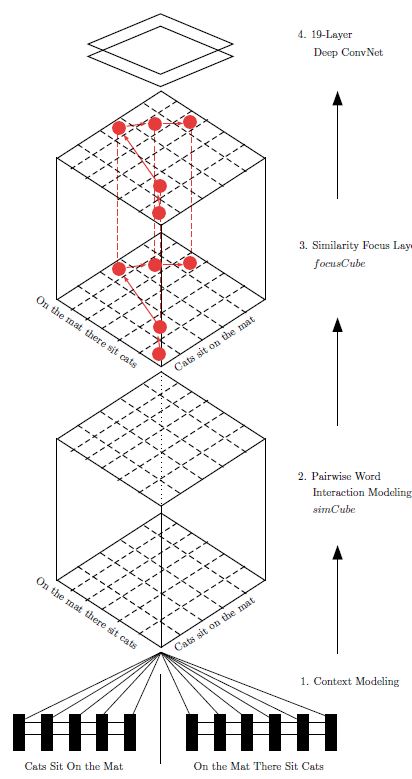
具体来说, 首先采用 BiLSTM 对输入的文本进行语义编码, 得到 t 对应的输出 $h_{1t}^{for}$ 和 $h_{1t}^{back}$。对弈 s 得到 $h_{1s}^{for}$ 和 $h_{1s}^{back}$ . 而后通过以下方式构造深度为 13 的 matching matrix .
- 1 - 3 表示 , 其中 , 其中
- 4 - 6 表示
- 7-9 表示
- 10 - 12 表示 , 其中
- 13 表示 indicator
构造过程用伪代码表示为

接下来构造 mask 矩阵, 该矩阵会在匹配程度较高的位置设置值 1, 其余位置 设为 0.1 。这样通过将 mask 乘以上面那个 matching matrix 对相应的信号进行放大缩小。用伪代码表示为

其中 calcPos 函数返回相对位置。 再往后就是深度卷积网络了, 对应的配置如下所示

Sentence Similarity Learning by Lexical Decomposition and Composition
前面的模型都是尽可能的去匹配 Q 与 D 间相似的部分, 但该论文认为, 不相似的部分也同样重要。论文将输入分解为相似部分和不相似部分,将二者加权求和送入 CNN 进行聚合, 最通过 线性层和 sigmoid 函数终计算相似程度. 论文的完整流程如下图所示
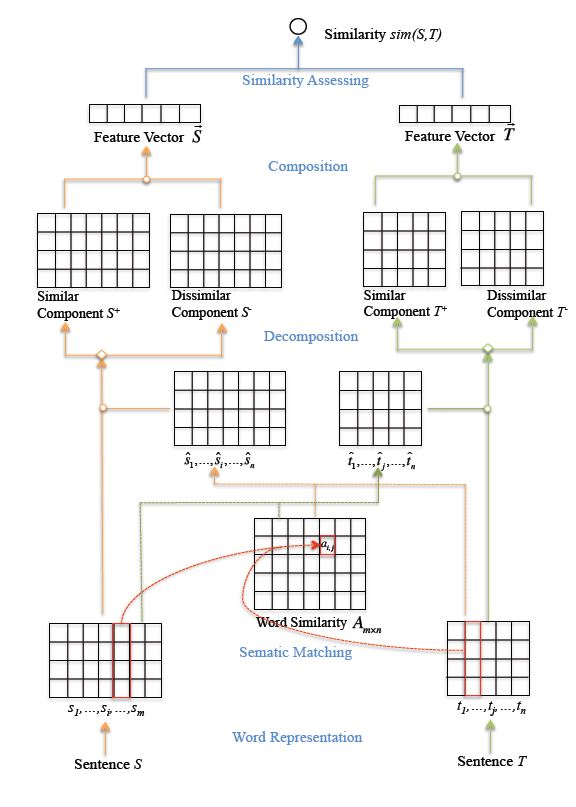
假设输入为 $ S = (s_{1}, s_{2}, \dots, s_{m})$ 和 $T = (t_{1},. t_{2}, \dots, t_{n})$。通过 T 和 S 我们可以构建相似匹配矩阵 $A_{mn}$。 A 中每个元素通过
得到。
接下来计算 , 其中 被定义为
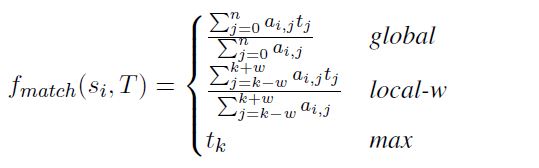
其中 global 考虑了整个 T 序列, max 部分只考虑了单独一个 t, 而 local-w 操作综合了以上两个, 其T 中的一部分(以 k为中心的前后 w 个).从另一个角度看,这其实就是从不从颗粒度上的匹配, 即 句子、短语、词级别的匹配。实验结果表明 max 操作效果最好。
有了 $\hat{s}$ 和 $\hat{t}$ 后我们将对 $s_{i}$ 进行分解得到相关部分和不想管部分。具体来说有 3 种分解策略 – rigid、linear、orthogonal。
- rigid 分解和 indicator 一样, 当 和 相等时, , 其中 表示相关部分, 表示不相关部分。反之则
- linear 分解,该方法计算 和 间的相似度 ,而后有 ,
- orthogonal 分解,正交分解, 将平行的组分分给 , 垂直的给
实验结果显示, rigid 的效果最差,因为它只考虑严格的相等,这个很好理解,至于 linear 和 orthogonal, 结果显示MAP中这两个效果差不多,单 MRR 上 orthogonal好一些,因此论文里最后用的是 orthogonal。
分解完后,将采用深层 CNN 来进行聚合操作得到低维向量表示, 最终通过线性映射和 sigmoid 给出 0-1 之间的相似值。
该论文的亮点是分解操作, 得到相似和不相似的部分,不过这个分解到底能从哪种程度上进行分解论文里没写,有时间研究一下。
BiMPM – Bilateral Multi-Perspective Matching for Natural Language Sentences
比较经典的双塔式结构, 在使用 BiLSTM 得到语义表示后通过四种匹配策略(Full matching, maxpooling matching, attentive matching, max attentive matching) 得到对应的交互匹配表示,最终再次采用 BiLSTM 的最终时间步输出进行聚合, 通过两个线性层和 softmax 计算相似概率。 模型结构如下图所示
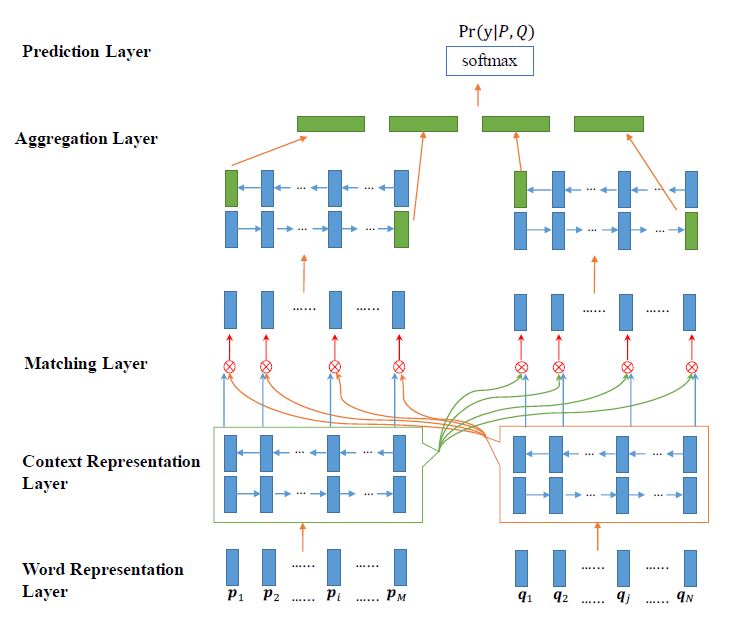
首先 word representation layer 对输入的词进行嵌入,可以用 word2vec 或者 glove。 context 表示层采用 BiLSTM 对句子进行语义编码,其中 对于文章 p 的第 i 个时间步的前后向输出为 , 查询 q 的第 j 个时间步的前后向输出为 .
matching layer 这细说一下, 以 P –> Q 的匹配为例(即 P 中的某一个 对整个 Q 序列计算余弦相似度, Q –> P 同理)。四个匹配方式如下图所示
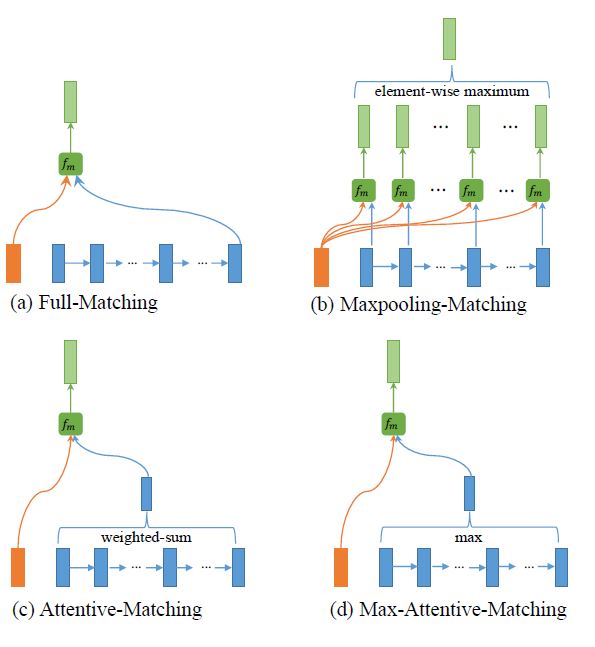
第一个 Full-matching, 用 P 中 和 Q 的最终时间步输出 / 计算余弦匹配函数。即
第二个是 maxpooling 匹配,它首先正常计算 与 Q 中每个元素的余弦匹配函数, 最终进行 element-wise maximum 选取每一行最大的元素作为最终向量表示的一部分。
第三个是 attentive 匹配,和注意力机制类似, 先分别计算 与 Q 中每个元素的余弦相似度,并归一化得到对应的权重, 并加权求和得到 Q 的聚合表示 , 最终用 与 计算余弦相似度匹配。
最后一个是 max-attentive 匹配, 上一个不是计算完权重后进行加权求和嘛, 这里变了, 只要权值最大的那个作为 Q 的聚合表示, 之后用该表示和 计算余弦相似度匹配。
对于这四个匹配函数, 作者做了消融实验, 结果表明每个都很有用, 移除后模型下降程度差不多, 因此都保留了。最终四个匹配函数加上前后时间步, 一共 8个向量连接在一起作为该时间步的新表示。
经过上一步 matching 层后, P 和 Q 都有了新的表示, 之后将新的表示输入到 BiLSTM 里进行聚合并计算 softmax 操作就可以了。
除此之外作者还对比了只用 P –> Q 和 只用 Q –> P 的模型, 结果显示模型效果下降了很多, 并且下降效果在 Quora 上是对称的, 但是在 SNLI 上是不对称的, Q –> P 更重要一点, 因此是否采用双向语义匹配是需要根据数据集来定的, 但解释论文里没写,不过如果复杂度可以接受的话还是都用了好, 毕竟效果至少不会下降 = =。
aNMM: Ranking Short Answer Texts with Attention-BasedNeural Matching Model
前面那些构建匹配矩阵后,很多都用 CNN 提取特征。这相当于认为这种匹配特征具有平移不变性,权值在不同位置的 word 中共享。作者认为这种共享是不合理的,因此基于此提出了基于 value 的共享权重方法。对于匹配矩阵来说,即卷积核中的权重不是位置固定的,而是输入的 value 所在区间对应的值。这个后面细说。
整个模型的结构如下图所示,这个是模型 aNMM-2, aNMM-1 相比于 2 只有一个 value-share 网络:
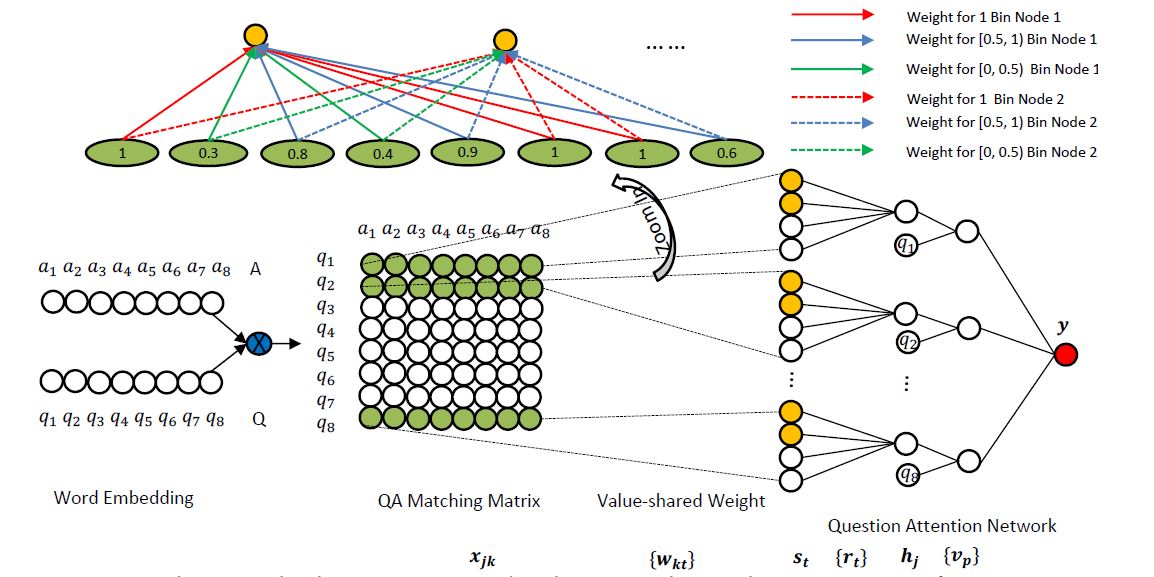
整体分为 4 层:输入层、 QA 匹配矩阵构建、value shared 层、 question attention network 层。
输入层没什么好说的,embedding 就完事了。匹配矩阵就是对应 term 间计算 cos 相似度。
接下来进入重点 value share 层,对于普通的 CNN,position -shared 的如下图左侧所示:
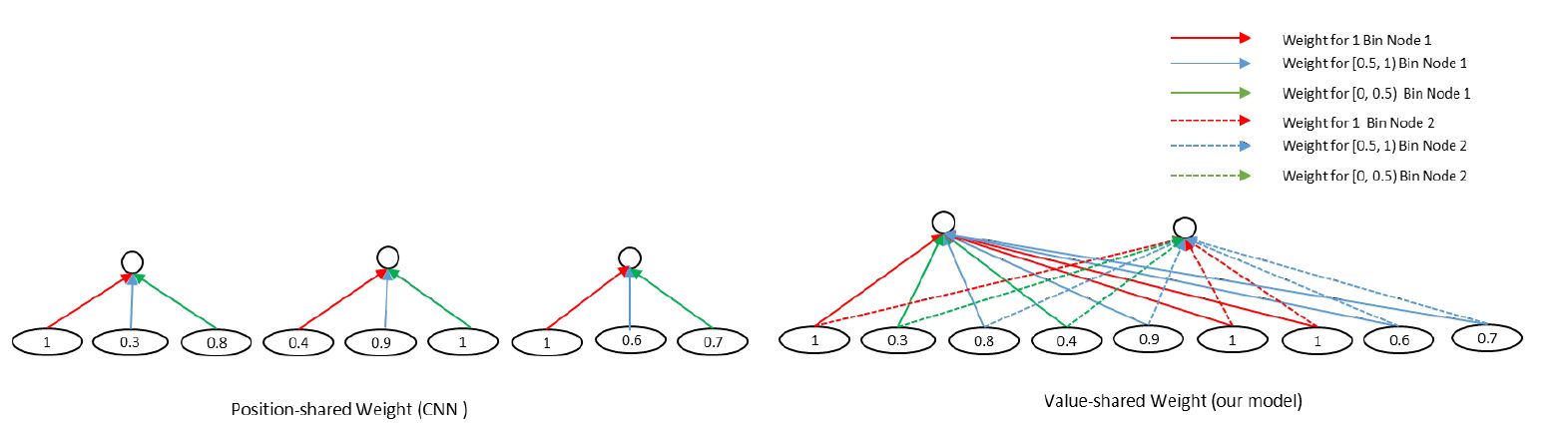
但我们扫描的是匹配矩阵,query 和 term 的匹配可能出现在任意位置上,并不一定是位置强相关的。且相同权重对结果的共享应该是一致的。因此作者提出这种 value-share 的方法,如上图右侧所示:
- 先按照权值的分布对其进行分桶:由于匹配矩阵是通过计算 cosine 得到的,因此范围在 -1 到 1 之间。所以作者采用 间隔 0.1 进行分桶,共得到 21 个分桶。
- 落到相同桶分区的 value 共享权值
通过该方式,可以将匹配矩阵转化为相同的维度而不同考虑输入矩阵的维度大小。
假设 w 表示从输入层到隐藏层的 K+1 维模型参数, 表示第 k个 bin 内所有匹配信号的和,对于给定的查询 q,第 j 个节点的 combine 分数为:
最后用 attention 层对其进行聚合得到匹配分数。经过前面的网络,对于每个 query - doc 对,都可以计算得到一个 M 维向量,向量的每个元素都表示 doc 与当前 query 中M 个 term 中每个 term 的相似度。
引入参数向量 v,通过计算它与 q 的乘积得到权值分布,而后对 h 进行加权求和得到最终的匹配分数:
ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs
本论文在 attention 在匹配任务中做了早期尝试。 分别在 卷积层和池化层引入 attention,将句子之间的相互影响整合到 CNN 中。因此每个句子的表示都考虑到了其对应的句子,这些相互依存的句子对表示比孤立的句子表示法更强大。
下图是没有加入 Attention 的 CNN 模型:
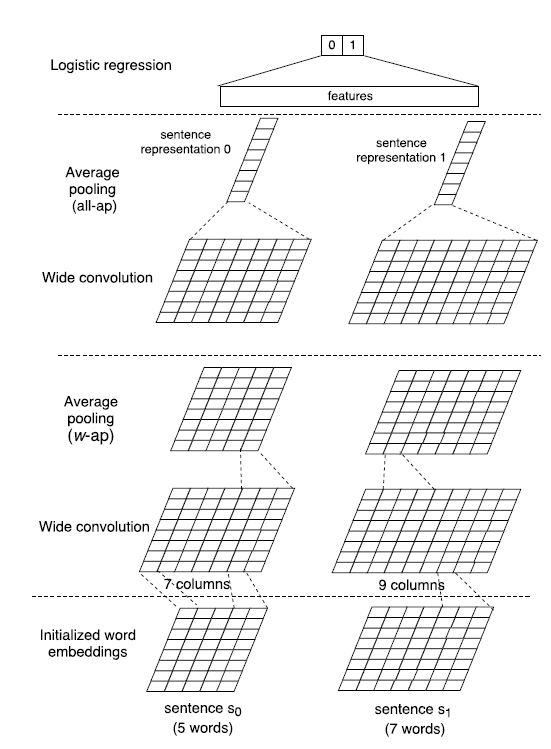
就是之前常见的类型,需要注意的是 这里面的 CNN 是 wide convolution 。假设 输入文本的长度为 s,维度为 d,卷积核宽度为 w。则卷积后的 feature map 大小是 s + w - 1。也就是说卷积后反而变宽了。不过不要紧,池化采用均值池化,窗口大小为 w,则池化后重新变为 s 列。这样就可以叠加多层的 wide convolution + avg pooling 了。
接下来加 attention,分别在卷积层和池化层或二者同时加。这样就有三个模型,分别是 ABCNN-1、ABCNN-2、ABCNN-3:
先在 卷积层加,结构如下图所示:
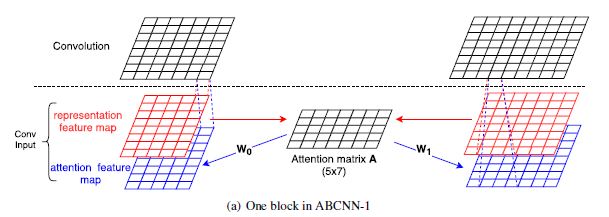
在卷积层之前加 attention,attention 是作用在原始输入向量的匹配矩阵上的。设原始输入向量用 和 表示,则匹配矩阵中每个元素为:
其中 match-score 可以是我们熟知的 cosine 或者 其他什么的。论文里提出一个,如果 x 和 y 越接近,匹配分数越接近于 1:
有了匹配矩阵后,引入 attention 矩阵 和 ,得到两段文本 query 和 doc 的最终加权特征向量
attention 后,将原始的句子向量 以及 attention 特征向量 用 concat 的方式连接作为接下来的输入进入到卷积层。
类似的,ABCNN-2 在 cnn 后做,结构如下图所示:
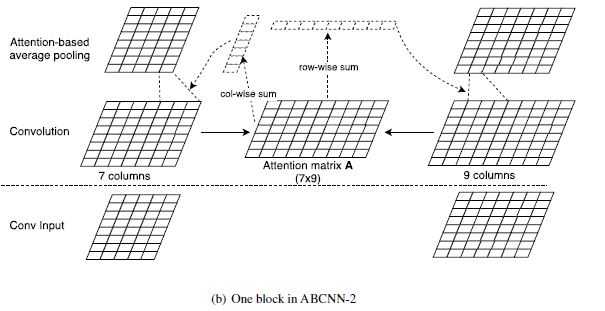
令 表示句子 query s0 的第 j 个单词,它的权重为 attention 矩阵中第 j 行的和, 表示的是句子 doc s1 的第 j 个单词:
则池化层的输出 可以通过对卷积层的输出 加权求和表示:
可以看到, ABCNN-1 由于需要两个额外的参数矩阵 和 来得到 attention 向量,而 ABCNN-2 不需要,因此 作者认为 1 更容易过拟合。
对于 ABCNN-3 就好说了,直接在卷积前和卷积后一起用,模型结构如下所示:
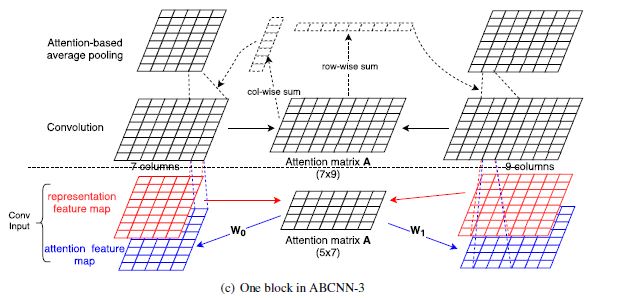
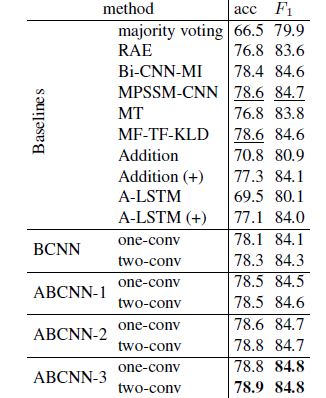
最终模型在 MSRP 上的表现如下所示:
MIX: Multi-Channel Information Crossing for Text Matching
MIX 是腾讯推出的工业落地的文本匹配模型。考虑到实际落地中的传统模型的一些缺点:
- 单词或n-gram被视为基本的语义单元,它忽略了自然语言的许多其他有用 方面,例如句法信息或句子之间的交叉引用。
- 他们很难很好地描述全局匹配和局部匹配之间的关系。 实际上,文本对中 关键部分或某些模式的匹配通常比全局结构的匹配更重要。
- 扩展性差,没有统一的集成机制 总的来说,许多上述模型都过于依赖神经网络的泛化能力以及训练数据的质量
针对以上问题, MIX 提出添加多种人工特征来最大化深度学习模型在各个层级的表达能力,并最小化 CNN 带来的信息损失。人工特征如下:
- Terms
- Phrases
- syntax
- Semantics
- Term frequence
- Term weights
- Grammer information
MIX还提出了一种新颖的融合技术,用于合并从多个渠道获得的匹配结果。 MIX中有 两种类型的通道,两个文本片段的特征可以通过它们进行交互。第一种类型是语义 信息通道,它表示诸如单字组,二元组和三字组之类的文本的含义。第二种类型的 通道包含结构信息,例如term权重,词性和命名实体,以及交互的空间相关性。在 MIX中,语义信息通道起相似性匹配的作用,而结构信息通道则用作注意机制。而 且,MIX使用3D卷积核来处理这些堆叠的层,从多个通道提取抽象特征,并通过多 层感知器组合输出。通道合并机制使MIX可以轻松地将新通道合并到其学习框架 中,从而使MIX可以适用于各种任务。
模型结构如下图所示:
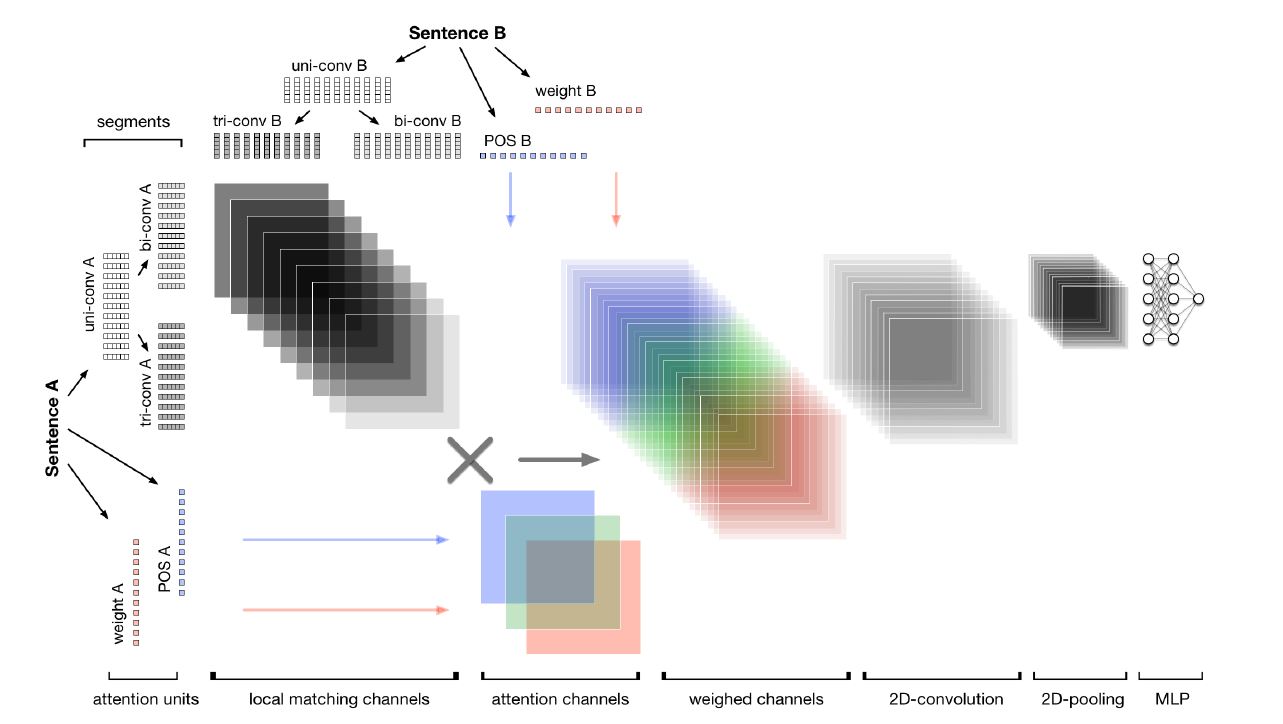
首先在输入这里,作者考虑了多种情况:
- 考虑 multigrams 输入,用 1, 2 , 3 gram 特征。这样,MIX可以找到对于一个文本片段最合适的语义表征,可能是words,terms或者phrases级别的。这里的目标是捕获交互矩阵不同级别最丰富的信息。对应 CNN 的核大小从 1 到3.
- 当考虑两个 句子时,匹 配两个关键 短语比匹配 两个普通短语具有更大的意义。用 tern 的 IDF 乘积作为 矩 阵中的每个 元素的初始 值。这样可 以过滤掉不 重要的词所 贡献的权 值。 把用IDF 得 到的这个看 作一个 mask 放到原始匹 配矩阵上, 得到加权匹 配矩阵图。如下图所示(图a 是正常的匹配矩阵,图b 是 term IDF 乘积,图c 是二者对应相乘后得到的匹配矩阵)

- 还可以考虑 POS 标签的匹配,毕竟两个实体间的匹配比名字和副词间匹配更重要。理想情况下, 给定丰富的训 练数据和可以 很好地概括的 模型,可以在 训练过程中自 动学习此特 征。 但是,在 实际应用中, 我们通常只有 有限的训练数 据,这些数据 可能会也可能 不会捕获POS 功能的强大影 响。 因此,引入一些与有用 的POS匹配有 关的先验知识 是必不可少 的。
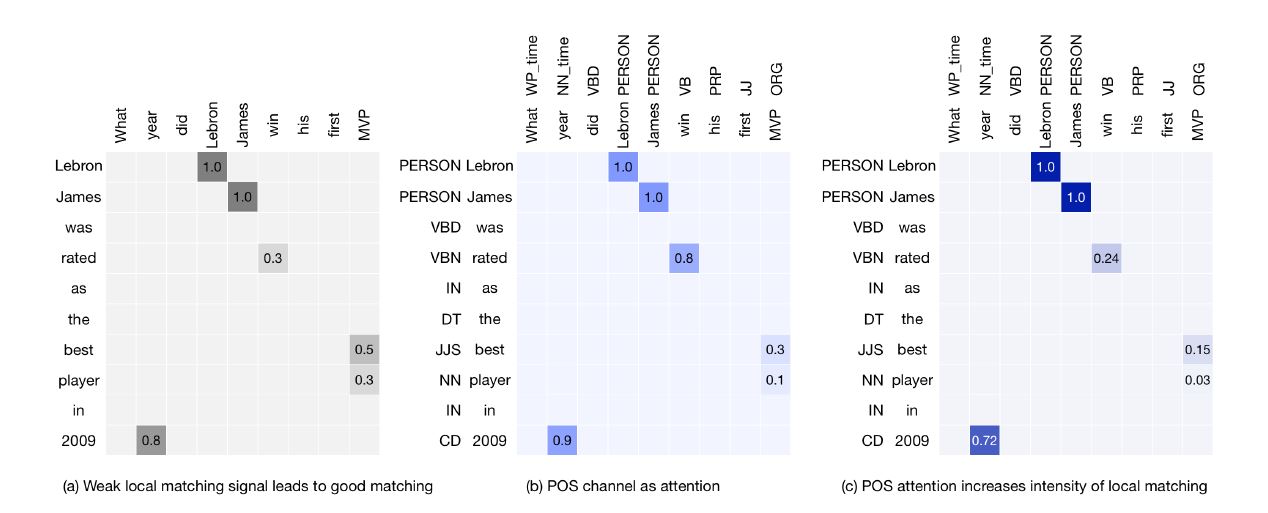
- 句子中单词 的位置也会 影响局部匹 配和全局匹 配之间的关 系。对于一些特定的任务,存在特定的空间匹配模式。以QA任务为例,question和answers的开头部分影响更大。通过训练spatial attention层,融合空间信息可以更好地捕获global matching和local mathcing。
得到上述 attention channels 后,我们需要提取有效特征,论文选用 CNN 来完成。卷积还具有两个有益的特性:位置不变性和组成性。因为空间注意层已经封装了 所有有用的位置信息,所以在此阶段额外的位置依赖性将只会给匹配结果增加更 多的噪声。因此,聚合方法应该只提取有意义的局部匹配信号而不考虑它们的位 置,并且方便地通过卷积实现此目标。它的第二个属性,即组合性,与语言的本 质是一致的。在英语中,最基本的构成部分是字母。通过将不同的字母组合在一 起,我们可以得到表达不同含义的不同单词。通过将不同的单词进一步组合在一 起,我们得到了短语和句子,它们可以包含更复杂的想法。卷积以类似的方式工 作,其中将小的局部局部特征合并为更高级别的表示。从直觉上讲,CNN会从 local 匹配信号一直到全局匹配结果的层次结构中提取特征。
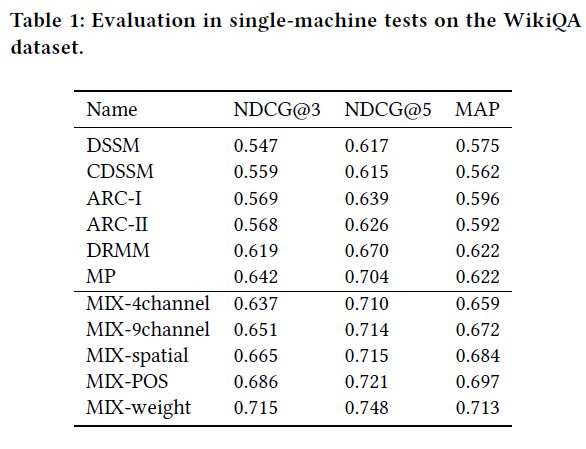
最终模型的评测效果如下图所示:
DIIN:Natural Language Inference over Interaction Space
DIIN 即 Densely Interactive inference network (密集交互推理网络)的简写。网络结构如下图所示:
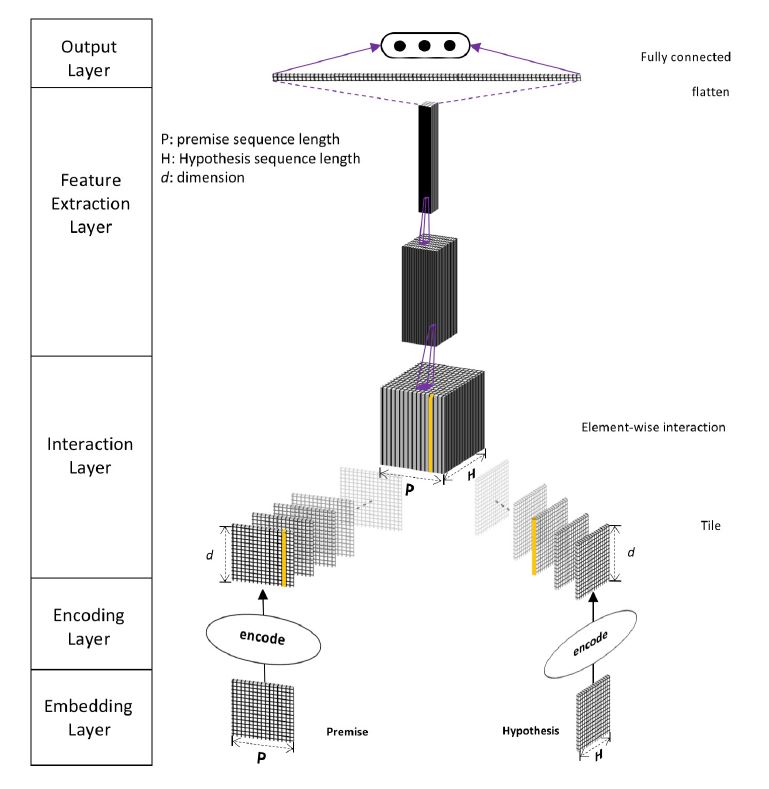
整个模型分为 embedding 层、编码层、交互层、特征抽取层和输出层。
对于输入, embedding 包含 word embedding 、 character embedding 、 syntactical feature 三种。 word 嵌入用 Glove, char 嵌入用 CNN 提取,再用 max pooling 得到 char embedding。 对于语法特征,包含 POS 和二进制精确匹配特征(EM)。将上面得几个 embedding 进行 concat 得到维度为 d 的向量表示。对该向量用两层 highway network 进行处理得到 和 。
为进一步提取信息,论文使用 self-attention 对上下文信息进行编码 得到向量 。 其中 self-attention 的匹配分数是通过 得到的。
将编码后的向量 和编码前的向量 进行连接,作为 fuse gate 的输入(和 skip connection 相似)。得到对应的输出
上述流程对 query 和 doc 通用,但二者不共享权重。
在交互层,将对qeury 和 doc 中的每个 term 计算匹配分数得到匹配矩阵,论文用的是 点积。
在特征提取层,论文采用 DenseNet 作为 DIIN 的卷积特征提取器。尽管论文实验表明 ResNet 效果良好,但 DenseNet 在保存模型参数方面有效。
输出层用简单的线性层个 softmax 进行分类。
QANet - Extending Neural Question Answering with Linguistic Input Features
论文提出,对于专业领域QA,一个有效的方法是先学习通用领域的,再在专业领域上做适应性训练。而学习通用领域普遍的知识一个很好的途径是利用句法、语义抽象的高层上丰富的语言知识表示。
作者分别利用了三个层次的语言学特征:POS 词性标记、依存句法、语义角色关系三种,其中
- POS 可以减少特定类型候选答案的数量。用 Spacy 工具获得
- 依存句法可以精准预测 Span 的边界。也是用 Spacy 工具获得。
- 语义角色标记对回答类似于“谁”对“谁”、哪里、何时、做了什么这类问题有帮助。
有了它们后,将对应标记做 embedding 而后 concat 起来。具体流程如下图所示
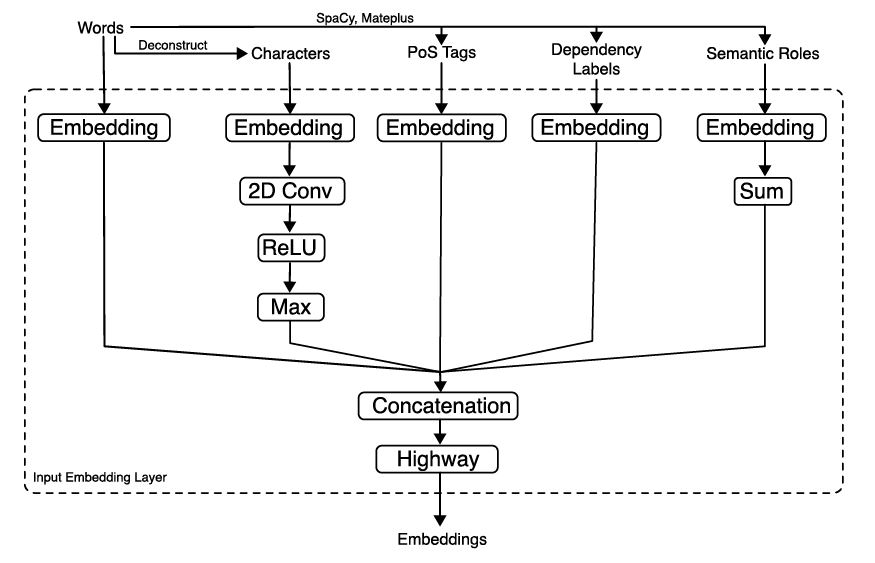
Match-SRNN:Match-SRNN Modeling the Recursive Matching Structure with Spatial RNN
本文提出将两个文本之间的全局交互的生成看作一个递归过程:即两个文本在每个位置的交互是之前前面(左、上、左上三个位置)之间交互和当前位置的词级交互的组合。基于这一思想,论文提出了一种新的深层结构,即Match-SRNN,来对递归匹配结构进行建模。首先,构造一个 Tensor 来捕捉单词级的交互作用。然后应用 Spatial RNN 递归地聚集局部交互,重要性由四种类型的门决定。最后,基于全局交互计算匹配得分。
模型结构如下图所示:
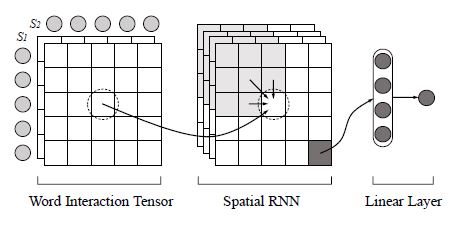
模型有三层: query 与 doc 的匹配矩阵层、 spatial RNN 层 和 输出聚合层。其中 spatial RNN 是我们关注的重点。
对于匹配矩阵的构建,对于 query 中的 第 i 个词 和 doc 中的第 j 个词 ,矩阵中的元素 :
嗯。。。。和 NTN 得到匹配矩阵一样。
接下来是 spatial RNN,作者用它来提取 query 和 doc 两段文本的关系。矩阵中每一个元素由其左侧、上方、左上 3 个相邻元素 及 当前的匹配矩阵元素 决定:
可以看出这是一个递推关系,而且不懂为啥这么组合。。。。我个人理解是通过这种方式,捕捉当前匹配点之前的可能语义组合,用 f 找出组合中语义关联性强的 词/短语 级别响应,从而捕获匹配信息。举个例子应该容易些,如下图所示:
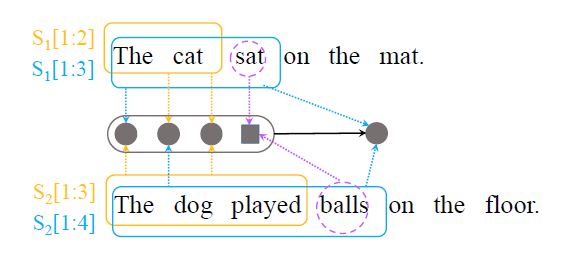
其中我们用 表示 。即句子 中的词 1 到 i-1 和 中的词 1 到 j 间的交互。在上图中, 表示 The cat, 表示 The dog played。假设 i 等于3,j 等于4,那么我们要用到 。可以发现, 的语义相关性更强,因此通过该方式可以捕获两个句子间的长依赖关系。
那 f 怎么定义呢?论文中使用了更改版的 GRU 模块。原始的 GRU 模块如下图左侧所示:
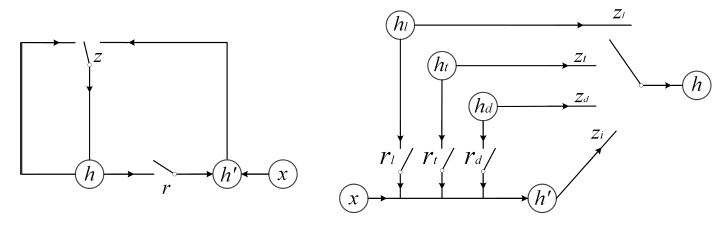
有一个 reset 门和 一个 update 门,但我们这里输入有 三个 h,因此论文对其进行更改,设计了一个三个 reset 门的 GRU,如上图右侧所示。除此之外,对于 update 门,对应于那三个 h 和原来的 $h^{‘} $。
得到交互矩阵后,用 MLP 进行聚合,pairwise loss 优化。整体比较常规,不多评价。
IARNN:Inner Attention based Recurrent Neural Networks for Answer Selection
传统 RNN 和 attention 结合的模型都是在 RNN 后加,但 RNN 后面时间步会聚集之前时间步的信息,因此 attention 权值计算的时候, 靠后时间步的词更容易得到更大的权值。为此作者提出在 RNN 之前或之中加入 attention,从而在避免权值偏移的前提下获得重要信息。
为此作者提出三种 Inner Attention based Recurrent Neural Networks(IARNN) 结构。
设 query 的向量用 表示, doc 的每个词输入向量用 表示,经过 RNN 的输出用 表示。
第一种叫 IARNN-WORD,结构如下图所示
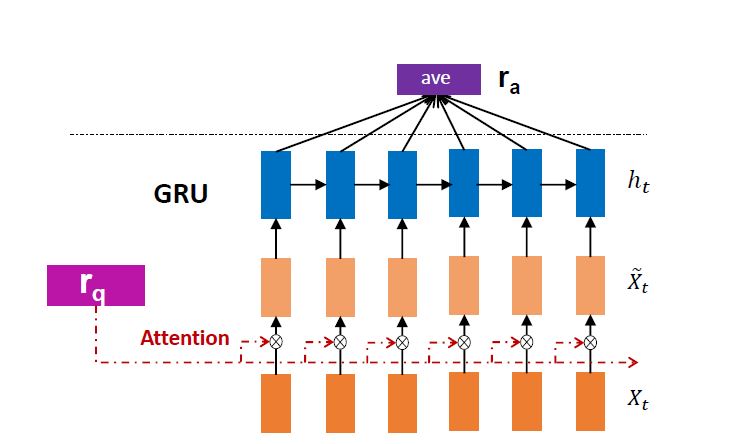
直接对 doc 输入的词进行 attention,将 attention 后的表示输入到 GRU 中。公式表示为
第二种叫 IARNN-CONTEXT,结构如下图所示
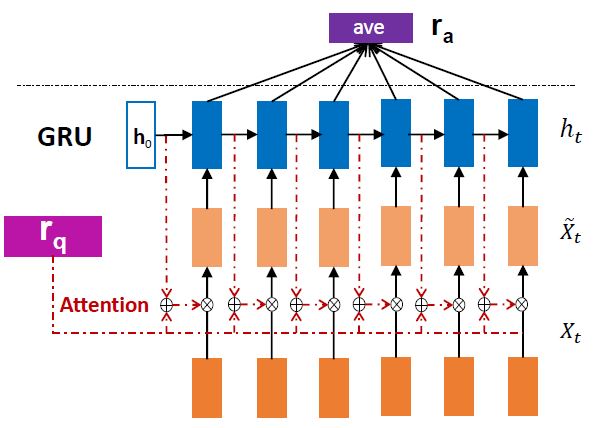
思想是每一个词可能单独看与问题无关,结合上下文信息就是跟问题是有关的,为了引入相关的上下文信息,将前一时刻的隐层输出加入到attention计算中,具体公式如下,其中 是可训练的参数:
第三种叫 IARNN-GATE,结构如下图所示
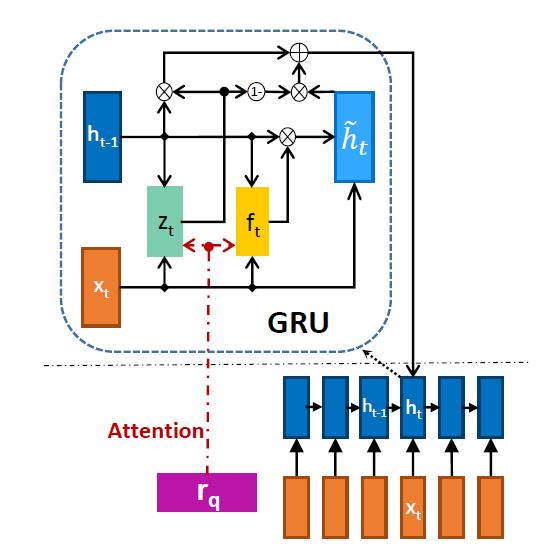
受到LSTM结构在解决RNN的梯度爆炸问题时所采用方法的启发,作者提出了直接将attention信息加入到GRU的每个门函数中,因为这些内部的门函数控制了隐层状态的信息传递,所以直接将attention信息加入到这些门函数中,去影响隐层的状态。具体公式如下:
还有一个是 IARNN-OCCAM,利用了奥卡姆剃刀原则:在整个单词集合中,我们选择能够代表句子的数字最少的单词。因此需要引入一个正则项,但由于不同类型的问题,它们对应答案中包含的与问题有关的词的个数是不同的,例如When和Who对应答案中相关的词更少,而Why和How对应答案中与问题相关的词更多。直接用超参数来控制这个正则项就不大好了,因此这里也利用网络去学习这个参数。具体公式如下:
实验结果分为两部分,一部分是验证 RNN 后加 attention 会带来 权值偏移问题,并查看论文提出的方法是否解决了这个问题。在单向 RNN 上的表现如下图所示,其中 OARNN 百世原始的,IARNN 表示修改后的网络。
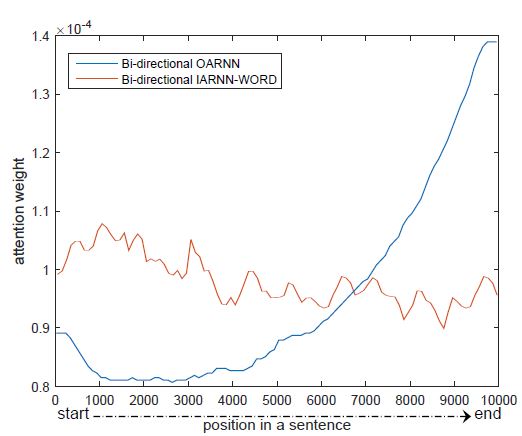
可以看出,原始 RNN 的权值确实在尾部更大,而改进后的模型消除了这种偏移。接下来在双向模型中进行试验,同样证明了这点:
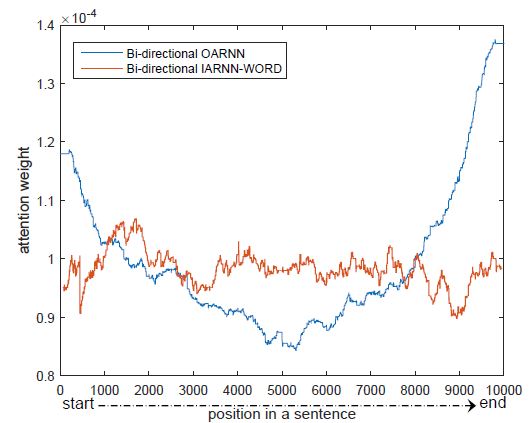
最终模型在 wikiQA 任务上进行试验,试验结果如下:
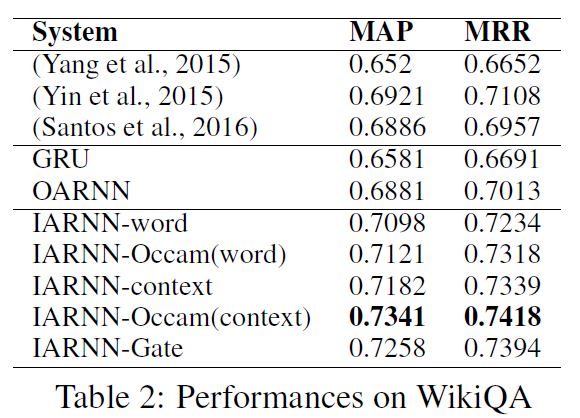
MwAN:Multiway Attention Networks for Modeling Sentence Pairs
模型中 用多种 attention 可以从不同角度提取交互信息,但直接把所有的表型进行 concat 效果不好而且维度太高了。因此论文提出一种多 attention 融合的方法。模型结构如下图所示:
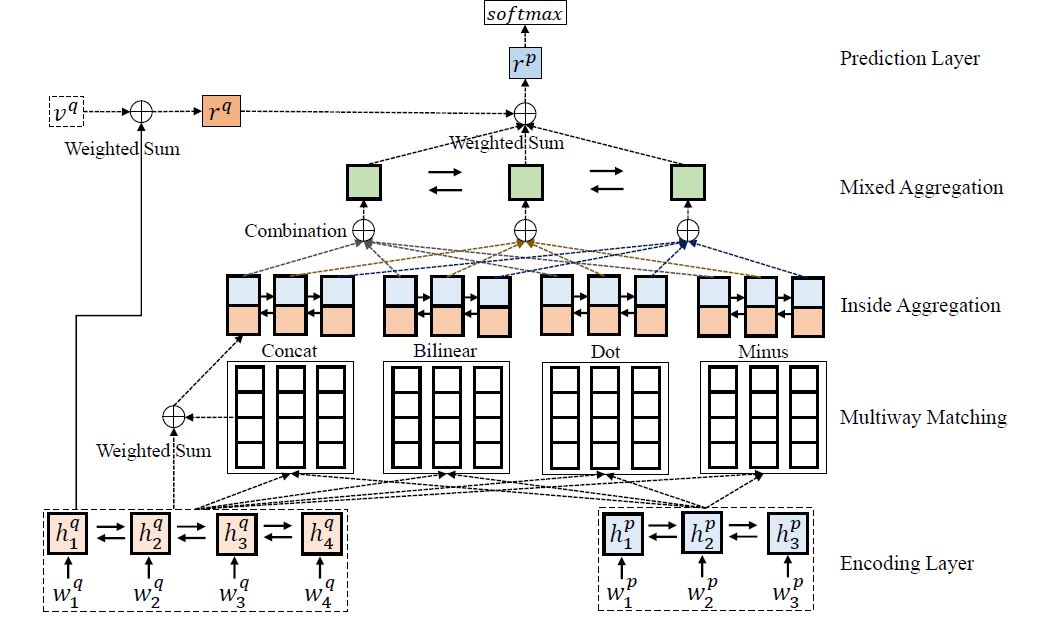
整个模型分为五部分: 编码层、 multiway matching、 inside aggregation、mixed aggregation 、 预测层。接下来分开说。
编码层首先 embedding 得到 Q 和 P 各自的 word 嵌入和 语义嵌入(语义嵌入用预训练语言模型得到,用 lm 表示),将二者 concat 后输入到 BiGRU 中得到最终 embedding 表示。公式表示有:
接下来是 multiway matching,通俗来说就是用四种方法计算 attention :
- concat attention:匹配分数为
- bilinear attention:匹配分数为
- dot attention:匹配分数为
- minus attention: 匹配分数
有了这么多 attention 怎么办?论文提出对每个 attention做 inside 的聚合,以 concat 的 attention 为例,先将 attention 后的和 attention 前的向量 concat 连接得到新的向量 。
为了判定该 attention 的重要性,论文采用一个 gate 对输入进行选择:
将处理后的向量输入到 BiGRU 中得到聚合后的输出:
同理可以用到其余几个 attention 上,得到对应的聚合表示 、 、 。
将上述 4 种 聚合后的 attention 输出在 mixed aggregation 层进行融合。大体思想是认为这四个 attention 作为一个整体看待,分别计算其中每个元素的饿权重并加权求和得到最终向量表示:
对 mixed 聚合后得到的表示输入到 BiGRU 中提取有效特征:
BiGRU 的输出再经过一个 attention 得到定长向量表示,而后经过 MLP 和softmax 进行分类,损失函数是交叉熵损失函数。该 attention 公式如下:
论文在 SNLI 数据集上的表现如下:
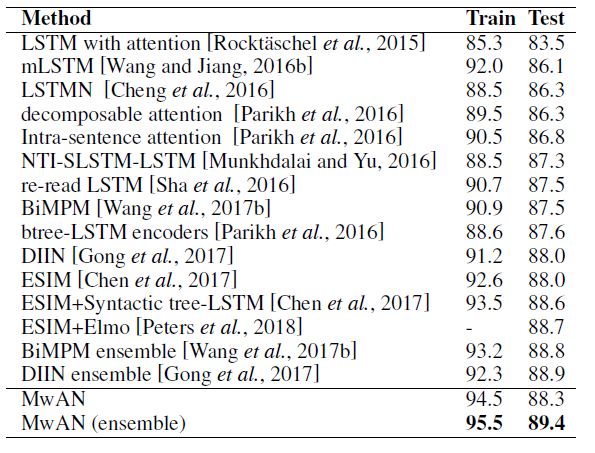
DecAtt – A Decomposable Attention Model for Natural Language Inference
很轻量级的一个模型, 作者利用 attention 获得句子的交互表示, 而后利用全连接层和加和池化进行聚合。持此之外, 作者还提出 intra-sentence attention, 即将输入的向量表示进行自对齐(self-aligned)作为新的输入表示,实验结果表明 intra-sentence attention 可以有效提升模型性能。
模型结构如下图所示
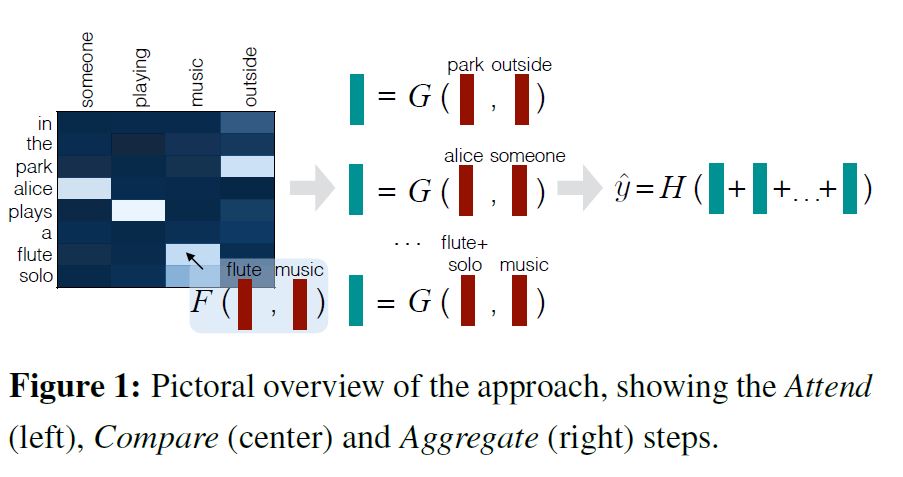
具体流程为:
- 首先 输入采用 Glove 得到词向量嵌入 $p_{i}, ~q_{j} $
- 计算 注意力权重(attention weights) , 其中 F 表示全连接 + ReLU 做线性和非线性变换
- 对权值矩阵归一化并加和平均得到新的软对齐表示
将原表示和软对齐表示进行连接输入到全连接层进行比较
最终通过加和方法进行聚合
剩下的就是用全连接层进行预测了。 除了上面的组块外, 作者提出可以用 Cheng 等人 提出的句内注意力(self-attention) 机制来捕获句子中单词之间的依赖语义表示:
距离偏置项 d 为模型提供了最小化的序列信息(这句话没太懂, 感觉是对于那些里的特别远的词, 该项会变大,使得模型能够考虑较远的依赖?) 同时保留了可并行化的特点。 对于所有距离大于 10 的词共享偏置, 也就是距离大于10 的话就都按照 10 算。 实验结果表明, 在embedding 后, 加上句内注意力可以有效提升模型效果。
ESIM – Enhanced LSTM for Natural Language Inference
很火的一个模型, 基于Parikh 的 DecAtt 改造得到的模型,作者认为 DecAtt 模型虽然考虑了句子内的对其匹配, 但没有考虑词序和上下文语义信息, 因此作者在匹配前后添加了 BiLSTM 层来获取更好的语义编码,充分利用时序和上下文语义信息。 最终该模型在NLI 任务上取得了很好的效果。不过这里其实带来一个小问题就是原论文 DecAtt 重点打的是快和参数少, 因为 DecAtt 只用了 attention 和 全连接层, 可以并行化处理, 用上 BiLSTM 的话并行化就会麻烦很多, 所以实际使用时可以权衡一下。
模型的结构如下图(左面那个)所示:
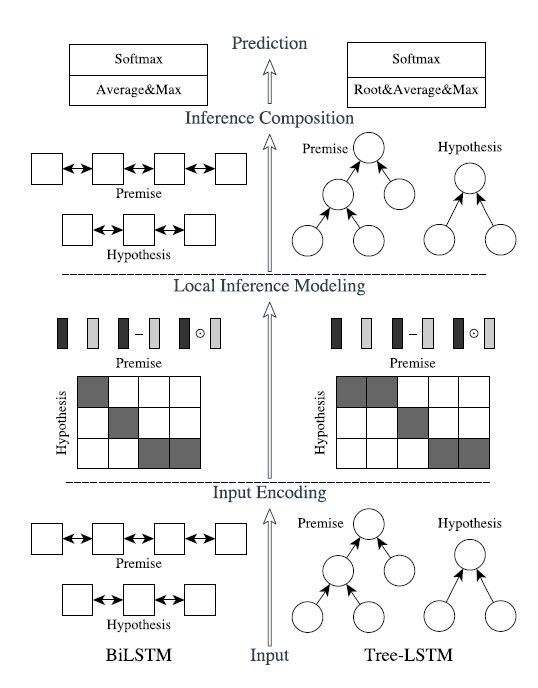
上图左侧可以分为四个部分: 输入编码(input encoding),局部推断模型(local inference modeling), 推断组件(inference composition) 以及聚合与相似度计算部分。重点是中间两个, 输入编码采用的是 BiLSTM,前向输出和后向输出连接在一起作为新的语义表示 。作者在后面的消融实验中证明,一个好的词表示对结果影响是很大的。我个人在实际使用中也发现,想要两句话交互的好,就必须再交互之前让模型知道每个词的含义,否则模型得到的只是任务和数据导向的特征,效果很差。因此可以考虑引入ELMo 或者加入生成类任务使得模型学习到足够好的词义信息。
局部推断部分可以帮助模型收集词义和语义匹配信息,通过直接匹配矩阵或者 soft / hard attention 对齐实现,帮助捕获前提和假设间子成分的交互。这部分和前面的匹配矩阵等交互目的相同。局部推断模型首先根据 计算匹配矩阵 E, E 中每个元素 。接下来对相似度矩阵的进行第 j 列相似度进行归一化得到对应的权重, 而后利用这些权重与对应的 加权求和得到 的交互表示。
其中 $l_{p}$ 和 $l_{q}$ 是 p 与 q 的长度 有了交互匹配的表示后, 接下来进一步利用这些表示, 得到 Enhancement of local inference information,也就是构建下面这个新的向量:
这个组合是需要好好考虑的,前两个比较好理解,那attention 前和后的放在一起,相当于残差网络。后面两个我就有点想不明白了,attention 前和 attention 后进行元素级别的差和点积,这是要计算他俩之间的相似性。那为什么要计算 attention 前和后的相似性呢?我猜测了一下,以差值这个来说,新的query 表示其实是 value 的加权求和,相当于在 key 句中提取出有意义的突出特征进行组合。比如 前提 是 “北苑路300号”, 假设 句是 “南苑路300号”,当 query 时”北”时, 它会更关注 “南”,因此 新的 qeury 表示主要由 “南” 构成。这样新的 query 和旧的 query 做差或者点积计算相似性就能捕获这种相同或者相反的关系。这也就对应作者希望借此锐化<旧 query, 新 query> 间的局部推断信息,来捕获像矛盾这种推断关系。这四个拼接起来就相当于给模型一个先验的更高层次元组间的交互。
再往后这两个 m将会被送入 BiLSTM 再次进行语义编码,需要注意的一点是,为了减少模型的复杂度和参数量,作者在将 mp, mq 送入 BiLSTM 前还用了一层线性全连接层 + ReLu 激活。而且 BiLSTM 是对 p /q 分别做的。
再往后就时池化聚合到固定的长度,作者认为 DecAtt 的 sum 池化会受到长度的影响,不鲁棒,因此同时采用最大或均值池化进行聚合。对于聚合结果进行拼接。消融实验表明这种操作可以增强模型的泛化性。
利用全连接层, softmax 进行分类。损失函数用的是多分类交叉熵损失函数。
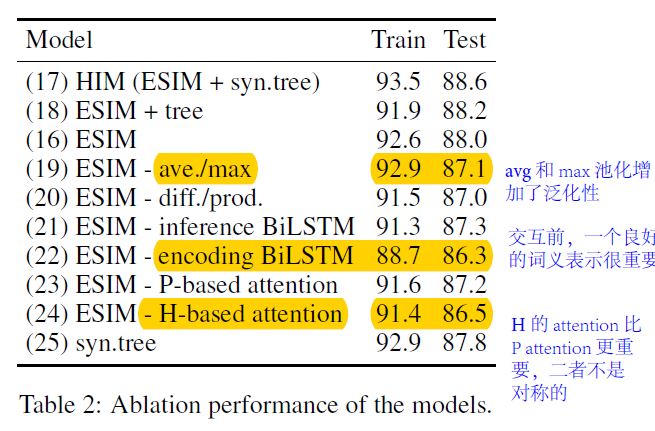
消融实验的结果如下图所示
这个模型我在一个项目里用过并进行了很多调整,在这里总结一下。首先是输入 + BiLSTM,这两个在我看来是绑定的,目的就是获得更好的词。有条件可以直接用 ELMo,没条件没数据的,像我这种的就加了一个生成模型在BiLSTM 后面,希望模型尽可能的学点词义信息。效果好了一些,对于长尾词有些效果。
中间匹配层就是获得一个良好的交互表述,文章里用了一个 co-attention,那类推下去,多层交互会更好么?Transformer 会更好么?多层 Transformer 或更好么?根据我的实验结果来看,这个受实验任务影响很大,语义更复杂的,涉及到深层次语义匹配的任务中,和句子长度比较长的任务里,多层的效果好。否则像地址匹配这种,一层就够了,后面加一个全连接都会破坏匹配的表现。
特征的组合就像上面说的,获得交互特征表示。其实从场面这些论文看下来,交互方式有很多种,但趋势很明显,大家逐渐的抛弃了纯矩阵匹配,转向 attention 的交互表示。毕竟纯匹配矩阵抛弃了语义信息,还不能捕获高级结构的交互。当然,春匹配矩阵在文本语义不连贯的时候依旧很有用。
最后的 BiLSTM 来捕获特征的组合,再加上 avg 和 max 池化。其实 这里有一个 BiLSTM 我一直有点想不明白,为什么会用 BiLSTM 放在这,毕竟前面聚合用的都是 MLP 或者 CNN,哪怕来一个 attention 也能理解。想了半天,有一个想法是输入到 BiLSTM 的输入其实是 由第一层 BiLSTM 开头的向量,虽然后面还跟着 attention 后的表示,差值,点乘 等,但本质上还是个序列。这么一想用 BiLSTM 就理所应当了 = =
除此之外,作者虽然在论文中只 提到 DecAtt, 但实际上 BiMPM 的思路和 ESIM 的相似,都用BiLSTM 进行语义编码,中间BiMPM 采用了更为丰富的 四种匹配策略:Full matching(和BiLSTM 的最后时间步做匹配)、max-pooling matching(cosine 后元素级别取最大的)、attentive match(attention)、max-attention match(hard attention)。而后再次用 BiLSTM 进行特征组合,取最后时间步的输出做聚合。区别是BiMPM 在match 后没有进行特征的组合,聚合也只采用最后时间步的输出而不是 max, avg 池化。
A COMPARE-AGGREGATE MODEL FOR MATCHING TEXT SEQUENCES
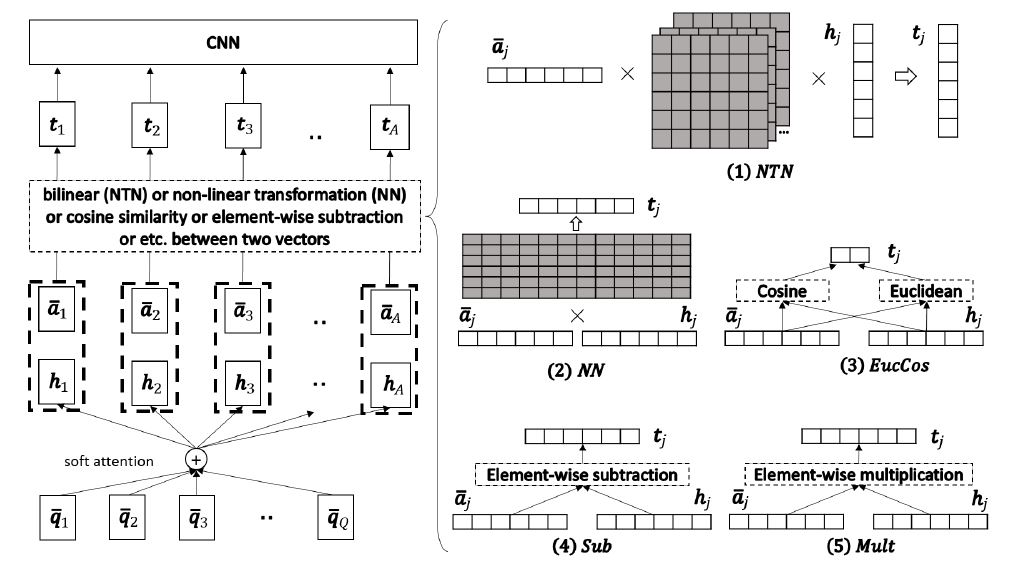
作者对之前的研究进行了总结, 提出通用的 “比较-聚合框架”(Compare-Aggregate),明确将模型分为预处理、attention表示、比较、聚合 四个步骤,并且对比了 5 个比较函数, 得出两个比较有效的比较函数。模型结构如下图所示
接下来看图说话, 以 Query 为例, 输入 , 经过预处理层, 采用只保留输入门的 LSTM 对其进行处理得到新的语义表示,保留输入门可以让网络记住有意义的词的信息。
其中 , .
之后 对 做 attention,得到 的新表示 H
其中 , 接下来进入比较层。作者对比了 5 个比较函数, 其中
- NEIRALNET(NN):将两个向量连接起来, 用线性层+非线性激活的方式,
- NEURALTENSORNET(NTN): 将两个向量看做矩阵, 用矩阵乘法的方式做, , NN 和 NTN 都没有考虑到语义相似度,因此接下来用了一些相似度度量函数来做这件事
- EUCLIDEAN+COSINE(EucCos):将两个向量的余弦相似度和欧几里得距离连接起来, , 但这又有问题了, 就是一下子都变成标量了, 丢失了很多语义信息
- SUB、MULT:既然想保留语义信息, 那就用元素级的点乘呗,这样得到的还是一个向量, ,
作者总结了一下, 认为 SUB 可以在一定程度上代替 欧几里得距离, 而 MULT 呢和 cos 很像, 因此作者就把 SUB 和 MULT 用 NN 的方式结合在了一起。。。实验结果也表明这个效果最好(其实从结果来看, 单纯的 NN/MULT 效果也没差太多, MULT 在一些任务中还超过了一点, 因此根据情况定用哪个吧)
聚合部分采用 CNN 来做。
MCAN : Multi-Cast Attention Networks for Retrieval-based QuestionAnswering and Response Prediction
在应用 attention 时,可以通过采用不同的 attention 得到不同的匹配特征,但如何结合这些特征却是一个问题。传统的采用 concat 来连接,但这回带来维度太高的问题。因此本论文提出 multi-cast attention 来解决这件事。
模型结构如下图所示:
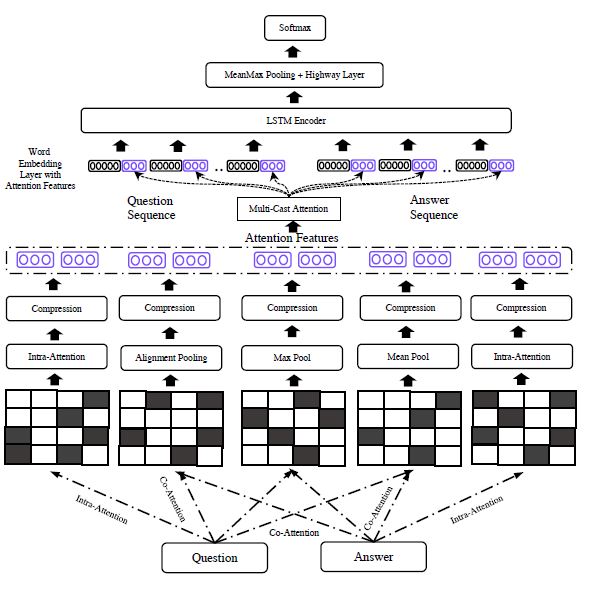
整个模型分为 5 层:
- 输入编码层:先 embedding,每个 term 的维度是 d。而后通过 highway encoder 进行映射,当输入为 x,输出为 y 时,highway的公式为:
其中H 是 ReLU 函数,T 是 sigmoid 函数。
- co-attention 层
先计算匹配矩阵,这通过对输入进行映射后进行点积得到:
也可以用其他的方法。之后开始做 attention,因为 query 和 doc 的输入长度不是固定的,因此论文提出 4 中 attention 方法:
- max pooling:用权值最大的,对于 query 来说就是对应 col 上最大的,对 doc 来说就是对应 row 上最大的。即:
- mean pooling:取对应 列或者行的权值均值:
- alignment Pooling:正常的 cross attention
- intra attention:就是 self-attention
上面这些 attention 可以提取不同的特征,接下来用 multi-cast attention 来结合它们。
设 是 query 或 doc 的表示(操作一样,用通用符号替代),设 co-attention 得到的表示用 x 表示,则对两个向量通过如下三种方式进行编码:
其中 FC 压缩函数,可以采用如下三种:
- Sum Function(SM):
- Neural Network(NN):
- Factorization Machines(FM):
通过以上步骤,每个 attention 都可以得到一个 3 维向量(三个压缩函数的输出),用它和原始的 word embed 连接输入到 LSTM 层。对 LSTM 的输出时间步,用 mean 池化和 max 池化 concat 起来(Mean-Max 操作)。这样对 query 和 doc 都得到一个固定的输出向量 和 。
对前面得到的表示与过点积、做差的表示进行连接,将其作为两层 highway 的输入,highway 的输出再进入 MLP 和 softmax 得到预测结果
Loss 用带正则项的 交叉熵损失函数。模型整体很复杂,很多地方存在的必要性我还没理解。等理解后再进行评论。
模型在 Ubuntu 数据集上的结果如下图所示:
HCRN:Hermitian Co-Attention Networks for Text Matching in Asymmetrical Domains
co-attention 是文本匹配应用中非常有效的注意机制。共同注意能够学习成对注意,即基于计算两个文档之间的词级亲和力分数来学习注意。然而, 文本匹配问题可以存在于对称域或非对称域中。例如,释义识别是一个对称的任务,而问答匹配和蕴涵分类则被认为是非对称的领域。本文认 为,与对称域相比,非对称域中的共同注意模型需要不同的处理方法,即在学习词级相似度得分时,需要引入词级方向性的概念。因此,现实空 间中共同注意常用的标准内积是不合适的。利用复向量空间的吸引性质,提出了一种基于复值内积(Hermitian积)的协同注意机制。与实点积不 同,复空间中的点积是不对称的,因为第一项是共轭的。量子力学常规操作。。。。里面有学物理的??
下图是它们网络的结构图:
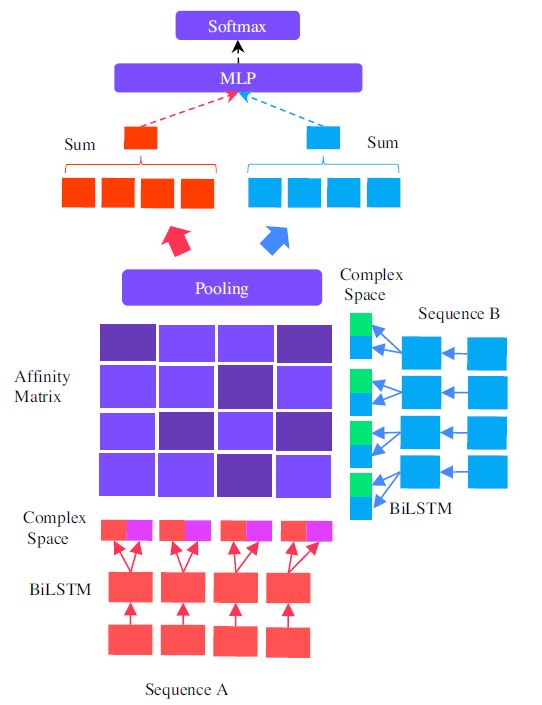
图中重点是映射到复数空间和仿射矩阵的构建,不过还是整体说一下。先是 embedding,而后经过非线性全连接层得到对应的表示,再将该表示输入到 BiLSTM 进行编码得到对应时刻的输出。
进入正题,论文提出将原始向量映射到复数向量的方法,对于两个复数向量的乘积叫 Hermitian Inner Product,定义为:
其中 。但 BiLSTM 输出的都是实值向量,怎么得到虚数部分呢?论文指出,虚数向量采用随机初始化或直接用 word embedding 的话,效果都不好,因此模型最终使用非线性映射得到复数部分,而后将两个实值向量复合成复数向量。比如对于向量 a,进行非线性映射 F,则得到复数向量 。
则 query 第 i 个 term 和 doc 第 j 个 term的匹配分数可以通过计算两者的 Hermitian Inner product,并取实数部分得到:
需要注意的是,该模型只是在 co-attention 模块中利用复数空间的性质,以此避免在处理复数的输入-输出中遇到的复数微分和 holomorphic 激活函数问题。而该模型通过一个映射得到复数部分并模拟复数运算,实际输入是两个实值向量,因此避免以上问题。
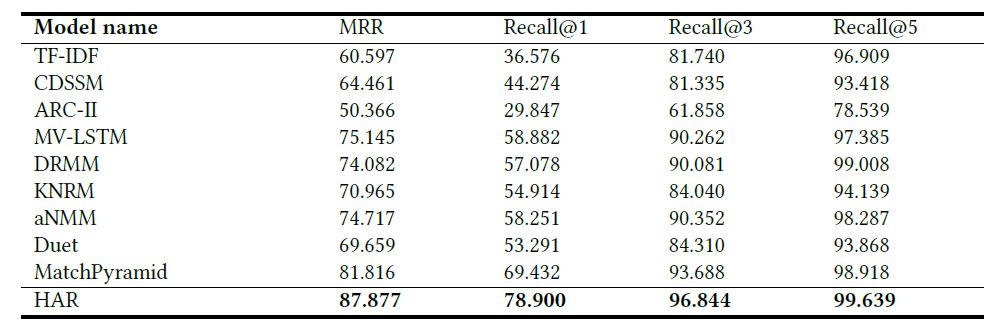
HAR:A Hierarchical Attention Retrieval Model for Healthcare Question Answering
对于医疗问答检索模型来说,query 一般比较短,而 doc 是由多个句子构成的,这就意味着 doc 会很长,并且有内部子结构。因此如果将 doc 的 attention 进行分层:先对句子内部,再对句子间做 attention ,这样得到的向量表示再和 query 做 attention 就会很合适。模型结构如下图所示:
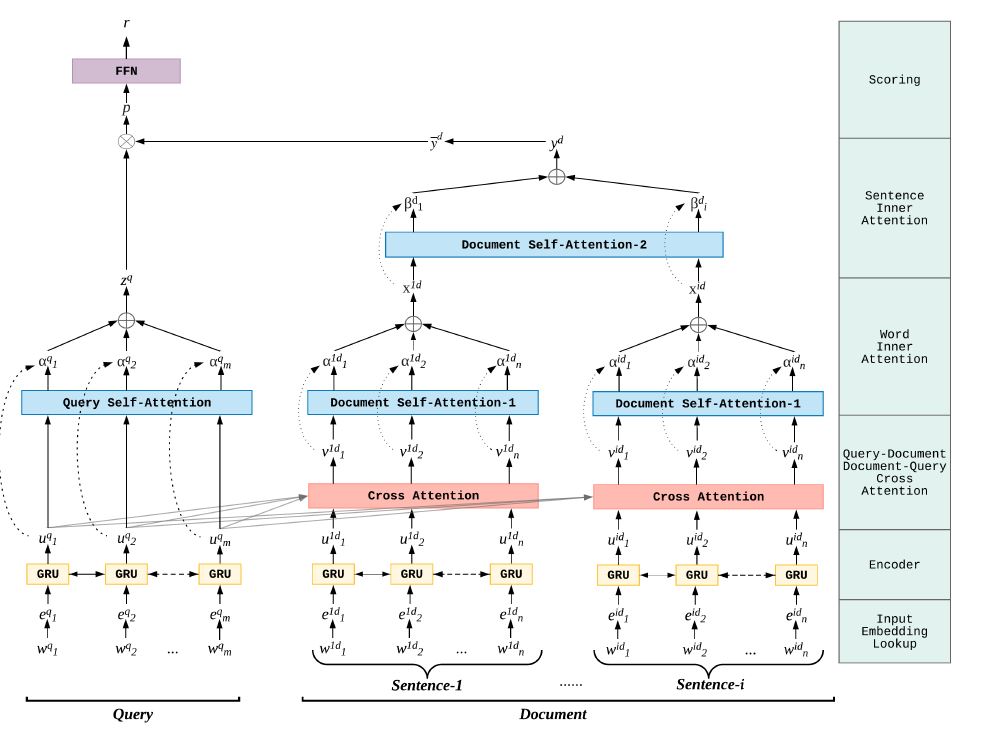
整体分为 5 层:word embedding、编码层、 query-doc 交叉 attention、query 内部 attention、doc 内部不同句子内和之间的 attention层、输出层。重点是 doc 内部的 attention,不过还是整体过一遍。
对于 word embedding 用Glove或 word2vec就可以。在编码层,用BiGRU 来做,对于 query,得到表示 ,doc 由于包含多个句子,因此应用句子级别的 BiGRU,具体来说就是先在每个句子上做,得到 ,其中 i 表示第 i 个句子,d是嵌入维度,t表示第 t 个时间步。如果有 l 个句子,则得到 lnH 维表示。
接下来是 query 和 doc 的交叉 attentio,这步就是 cross attention,匹配矩阵中每个元素为 。 做完 corss attention 后,将得到的结果进行拼接:
其中 表示 cross attention 后 doc 的结果, 是 cross attention 后 query 的结果。
接下来做 query 内部的 attention ,这个就是 self-attention,匹配分数计算公式为:。
query 做完内部 attention后,就是 Doc 的了,根据前面的说法,先做句子内部的,而后做句子之间的。对于句子内部的,和 query 的一样,都是 self-attention,得到 。在句子之间的 attention 和 句子内部的类似,都是 self-attention,只不过每个元素是句子的 attention 表示,最终得道 doc 的 attention 表示 。
得到 query 和 doc 的表示后,用 MLP 进行降维,再通过点积得到匹配分数,最后通过 MLP 得到最终匹配分数。整篇论文的思路还是很清晰的,尤其是QA 问题中,候选文本的长度相当的长,如果简单用 cross attention 的话,矩阵将会非常大。
DAM – Multi-Turn Response Selection for Chatbots with Deep Attention Matching Network
百度 2018 年提出的模型, 作者认为虽然 BiLSTM 能够捕捉序列的前后语义信息, 但代价比较大, 受到 Transformer 的启发, 作者提出了使用两种注意力机制来获取表示和匹配信息的模型。模型的结构模型如下图所以
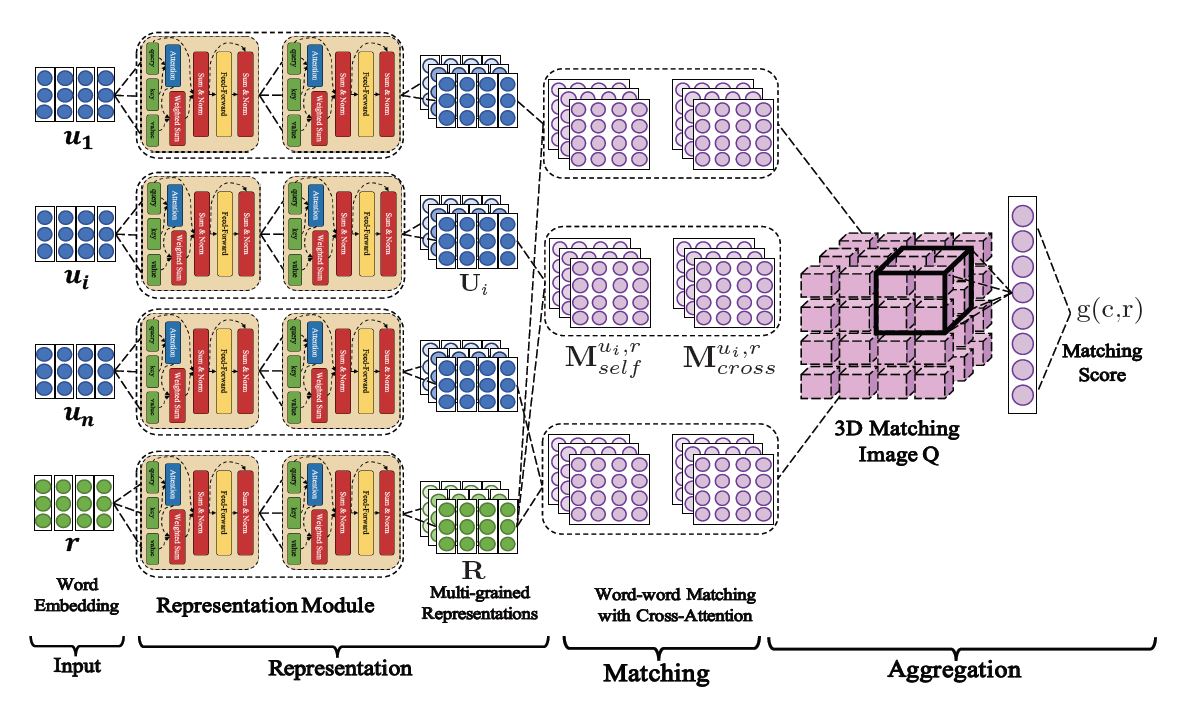
可以看到模型被分为 4 部分, input, representation, matching, Aggregate 这四部分, 还是比较经典的结构的。对于input, embedding 采用 word2vec 得到。
对于 表示部分和匹配部分用到的 attention 组件, 作者使用 attentive module, 它是根据 Transformer 改变得到的, attentive module 的结构如下图所示
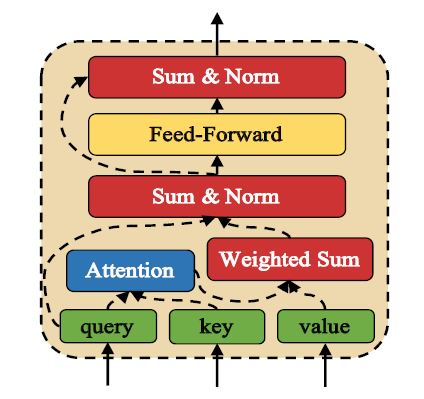
输入为 query –> , key –> , value –> 。
首先根据 Q 和 K 计算 scaled dot-product attention, 之后将其应用到 V 上, 即
模块中的 Norm 用的是 layer Norm. 激活函数用的是 ReLU。以上模块被记为 AttentiveModule(Q, K, V)
定义了 AttentiveModule 后, 表示层就是对输入的相应 R 和 多轮句子 U 分别用 该模型, 实验表明 5 层 self-attention 效果最好。
matching 部分可以匹配到段落与段落间的关系,包含 self-attention-match 和 cross-attention-match两种
其中 和 根据 self AttentiveModule 得到。对于 cross-match
最终将每个utterance和response中的所有分段匹配度聚合成一个3D的匹配图像Q。 Q再经过一个带有最大池化层的两层3D卷积网络,得到fmatch(c,r),最后经过一个单层感知机得到匹配分数。
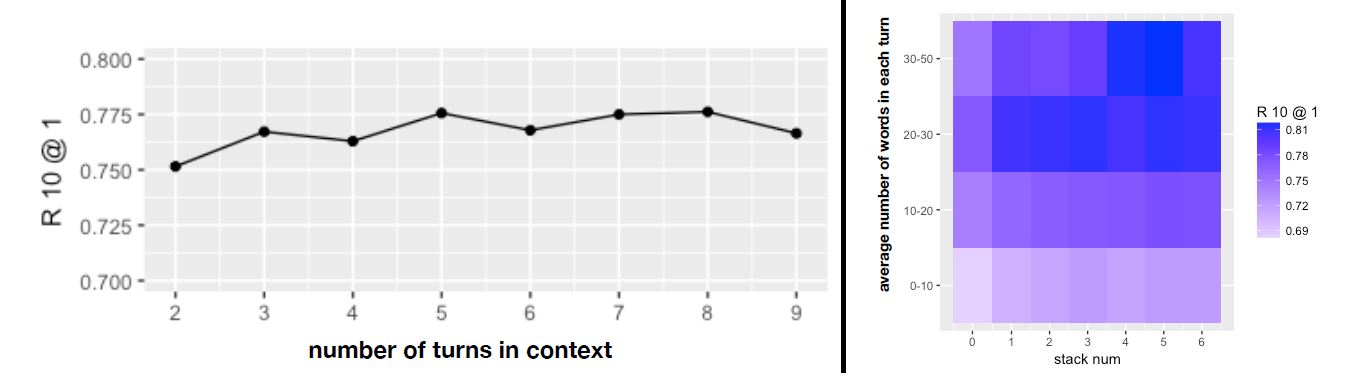
为了证明模型的有效性和必要性, 作者设计了一系列实验, 如 DAM-first 和 DAM-last 是只考虑第一层和最后一层 self-attention,但效果都不如 DAM 整体, 因此证明了使用多颗粒表示的好处。 还有 DAM-self 和 DAM-cross 是只用 self Attention match 和 cross attention match,效果也下降了, 表明选择响应时必须共同考虑文本相关性和相关信息。
对于具有不同平均话语文本长度的上下文, 堆叠式自注意力可以持续提高匹配性能, 这意味着使用多粒度语义表示具有稳定的优势。还有对于 0-10 个单词的部分效果明显不如长的, 这是因为文本越短, 包含的信息就越少。 对于长度超过 30 的长话语, 堆叠式自注意力可以持续提高匹配性能。但所需要的堆叠层数要越多, 以此来捕获内部深层的语义结构。
HCAN - Bridging the Gap Between Relevance Matching and Semantic Matching for Short Text Similarity Modeling
作者认为文本匹配大体上可分为两种:关联匹配和语义匹配。其中关联匹配更看重字符上的匹配,而语义匹配则更看重实际含义上的匹配。通常来说,针对这两种匹配任务所设计的模型不是通用的,为此作者提出了一个可以同时在两种任务上表现都很好的网络 HCAN(Hybrid Co-Attention Network)。
该网络包含三个部分:混合编码模块,相关性匹配模块和 co-attention 的语义匹配模块。整体的模型结构如下所示:
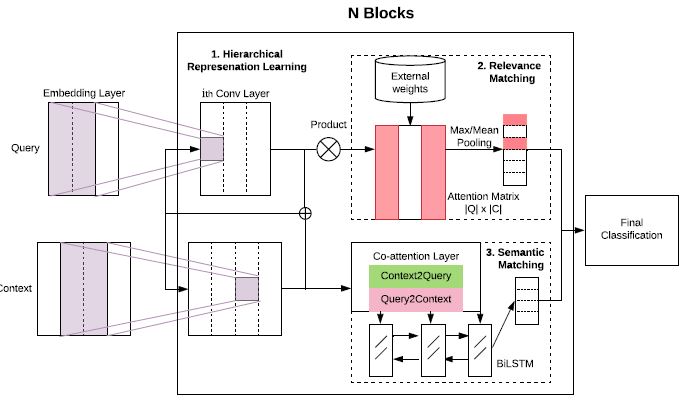
第一层是一个混合编码模块,作者分别尝试了 Deep(堆叠 CNN)、Wide(同一层不同大小卷积核)和 BiLSTM 三种编码方式。这三种编码器代表了不同的权衡,基于 CNN 的更容易并行化处理,同时也允许我们显示的通过控制窗口大小获得不同粒度的短语特征,这在相关性匹配中很重要。同时更深的 CNN 可以通过组合获得更大的感受野得到更高层次和更整体化的特征。而 BiLSTM 的上下文语义编码则更看重整体的语义信息和位置相关信息。
第二部分相关性匹配,首先计算混合编码层输出(, )的相关性匹配矩阵
而后在 context columns 上做 softmax 将其转化为 0-1 之间的相似性分数 。接下来对于每个 query 短语 i,分别采用 max 和 avg 池化来获得更显著的特征表示。
Max 池化可以得到最显著的匹配特征,Avg 特征可以从多个匹配信号中获益,但可能会受到负面信号的干扰。到这里我们就乐意将它们两个连接起来用了。但论文有一个更好的想法,就是针对 IR 等任务来说,我们可以赋予各个 Term 不同的权重,这个权重可以是 IDF 或者其他的什么权重。即
第三个是语义匹配,论文里是用 co-attention 来做,即堆叠的 Query-context 和 context-query 的 attention。需要注意的是,语义匹配和第二个是并列的。第一个是 bilinear attention
REP 是将输入向量扩展到 的维度。有了相似矩阵后,则有
我们就得到了query 和 context 的交互语义表示。接下来用 BiLSTM 对它们的组合进行语义编码:
最终结合第二部和第三部的输出放进 MLP + softmax 进行分类
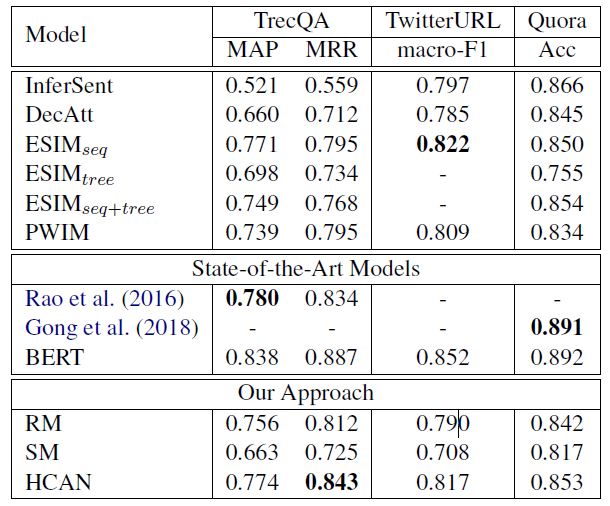
下图是HCAN 与各个模型的对比结果,其中 RM 是只用关联匹配(第二个),SM 是只用语义匹配(第三个)部分。我们发现,在这三个数据集上,关联匹配(RM)比语义匹配(SM)具有更高的效率。它在TrecQA数据集上以较大的优势击败了其他竞争性基线(InferSent、DecAtt和ESIM),并且仍然可以与TwitterURL和Quora上的基线相媲美。这一发现表明,对于许多文本相似性建模任务,单靠软项匹配信号是相当有效的。然而,SM在TrecQA和TwitterURL上的性能要差得多,而在Quora上,SM和RM之间的差距减小了。通过结合SM和RM信号,我们观察到在所有三个数据集中HCAN的一致有效性增益。
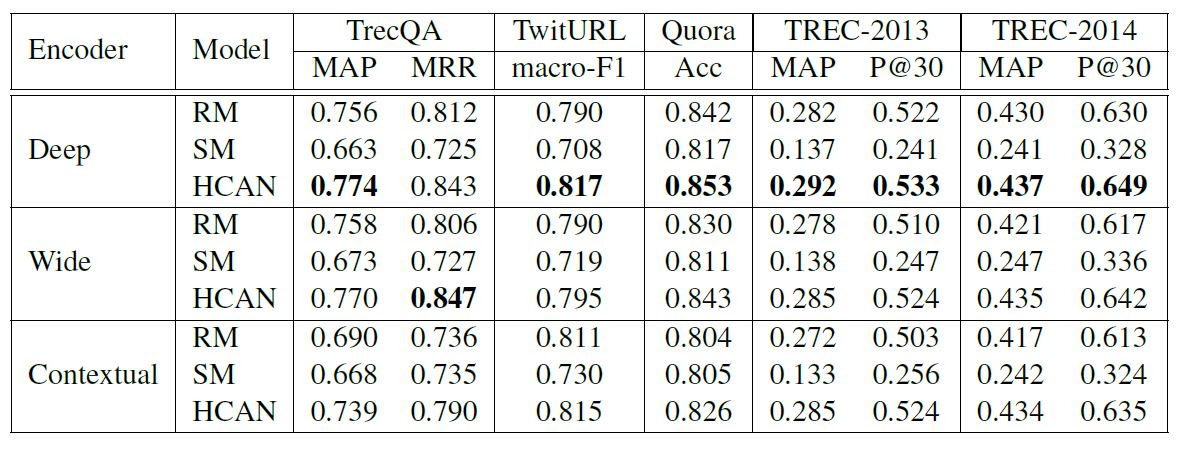
下图是比较不同语义编码层的区别,整体来说,当关键字匹配更重要时, CNN 可能获得更好的结果,更看重语义和长距离依赖时, 上下文编码更好。
至于 RM 和 SM,SM 往往需要更大的数据集才能获得较好的表现,因为它的参数空间更大。对于所有任务来说,将二者进行结合都可以得到一定的增强。
相关性匹配
DRMM: A Deep Relevance Matching Model for Ad-hoc Retrieval
成功的相关性匹配需要正确处理精确匹配信号、查询项重要性和不同的匹配要求。但目前的模型(DSSM, ARC-I )等是为语义相关匹配设计的,在 ad hoc 检索任务中表现不好。作者认为这是因为检索任务是相关性匹配而不是语义匹配。
为此论文提出 DRMM 模型,模型结构如下所示:
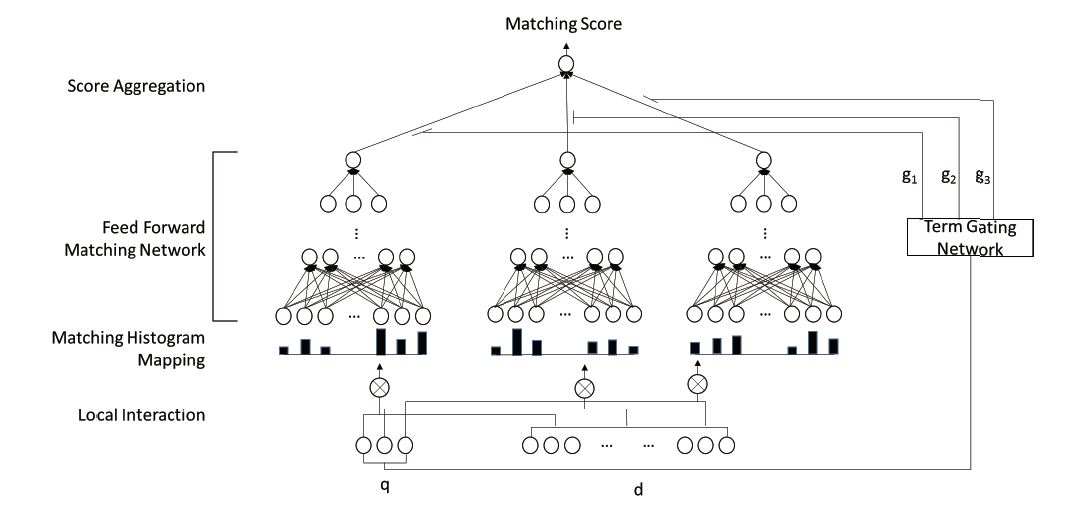
论文把 query 和 doc 分别表示为由 M 和 N 个 term 组成的 term 向量:
模型首先计算 local interaction,而后计算 matching histogram mapping。即先将 query 和 doc 的 term 两两比对,计算相似性,再将相似性得分放到对应的直方图区间内。比如query: car ; document: (car, rent, truck, bump, injunction, runway)。query和doc两两计算相似度为(1,0.2,0.7,0.3,-0.1,0.1)。将[-1,1]的区间分为{[−1,−0.5], [−0.5,−0], [0, 0.5], [0.5, 1], [1, 1]} 5个区间。落在0-0.5区间(第三个区间)的个数有0.2,0.3,0.1共3个,所以最终表示为:[0,1,3,1,1]。
上面例子中是一种做法,论文还提出了其他的方法,总结如下:
- Count-based histogram(CH):这种方法使用直接计数的方法进行分桶计算。也就是说先计算原始的相似度(通过cosine等),然后进行等距分桶(bin)后,统计每个桶(bin)的数量,得到的就是个基于计数的直方图
- Normalized Histogram (NH):在CH的计数基础上做了归一化,确保所有直方图的分桶都在一个区间范围
- LogCount-based Histogram (LCH) :对CH的计数直方图取log对数,这个在搜索引擎里主要也是为了迎合大多数query和doc的分布都是pow-law的,取对数后pow-law分布的数据会更加服从线性分布。
得到每个 term 的直方图表示后,将其输入到 FFN 中,而后聚合得到匹配分数。公式表示为:
其中第一个公式表示 query 和 doc 间 term 的交互并得到直方图分布的过程。最后一步里的 是 第 i 个 query 和 doc 的参数权重,通过 query 的 softmax 归一化得到:
其中 表示 query 中第 i 个 term 的向量。
论文结果如下图所示,确实比语义匹配模型要好很多。
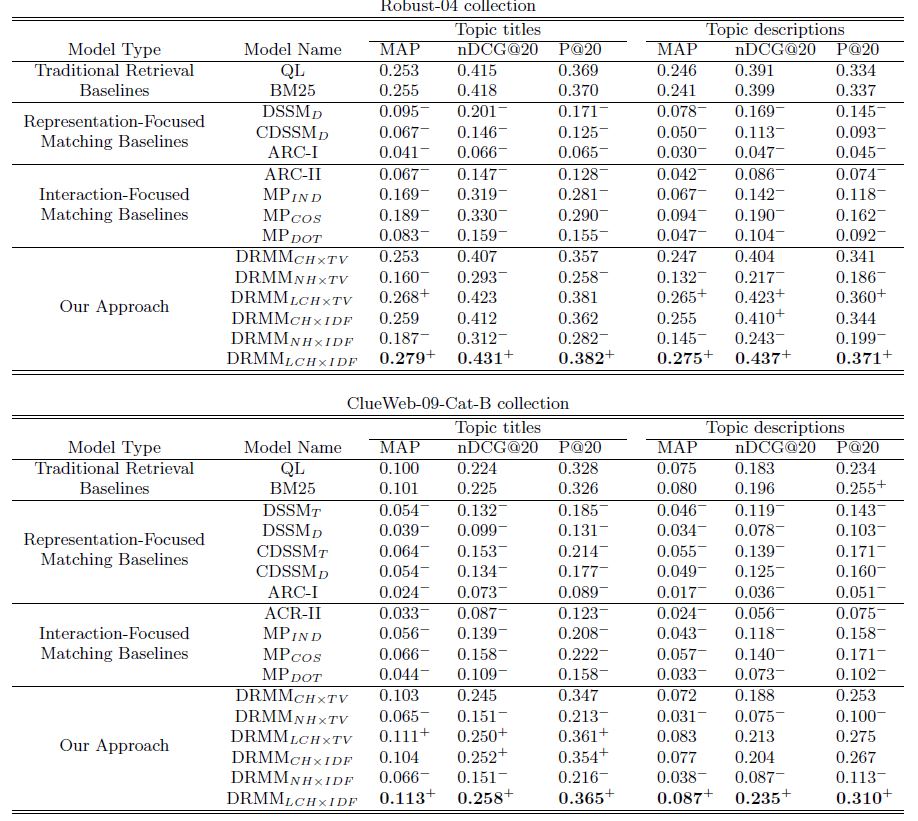
从结果发现,三种 直方图处理方法中,最好的时 LCH,也就是取对数的版本,这个比较符合检索的特征。第二好的竟然是 CH,它竟然比 归一化的 NH 好,而且好很多,说明归一化操作破坏了相似性的分布。
最后用 IDF 来计算聚合分数的效果比用向量的好那么一丢丢,而且最主要的是 IDF 快呀,一个标量。
再看结果,MP 时 MatchPyramid 模型,IND/COS/DOT 就是那三个相似性衡量方式, DOT 竟然比 IND 差那么多? MP 里不是说 DOT 最好麽? DRMM 比 MatchPyramid 要好的多。这都是为啥。。。。。。论文给出的解释是 MP DOT 效果差说明相似性匹配(非精确匹配)在检索类任务中不适用。那为啥 COS 还能用呢?按照这个推论, MP 效果不好的原因应该就是 CNN 没有显示的捕获精确匹配信号特征,而 下面的 RBF kernel 方法相当于用 soft-TF 来显示的用精确匹配特征所以有效。但 PACRR 却很好用,它也是匹配矩阵 + CNN 的方法做的,只不过采用多种大小的卷积核来捕获 n-gram 特征,那可不可以猜想并不是 CNN 在检索匹配中不行,只是需要捕获多粒度信息,也许 MP 加上多粒度也能变好?
K-NRM: End-to-End Neural Ad-hoc Ranking with Kernel Pooling
论文 提出了一种基于核函数的文档排序神经模型K-NRM。给定一个查询和一组文档,K-NRM使用一个 translation 矩阵,该矩阵通过单词嵌入来模拟单词级的相似性。除此之外还引入一个新的 kerner pooling 技术,该技术使用 kernel 来提取多级soft match特征。随后连接一个学习排序层,该层将这些特征聚合到最终的排名分数中。整个模型是端到端训练的。排序层从 pair-wise 排序损失中学习所需的特征参数。
整个模型结构如下图所示:
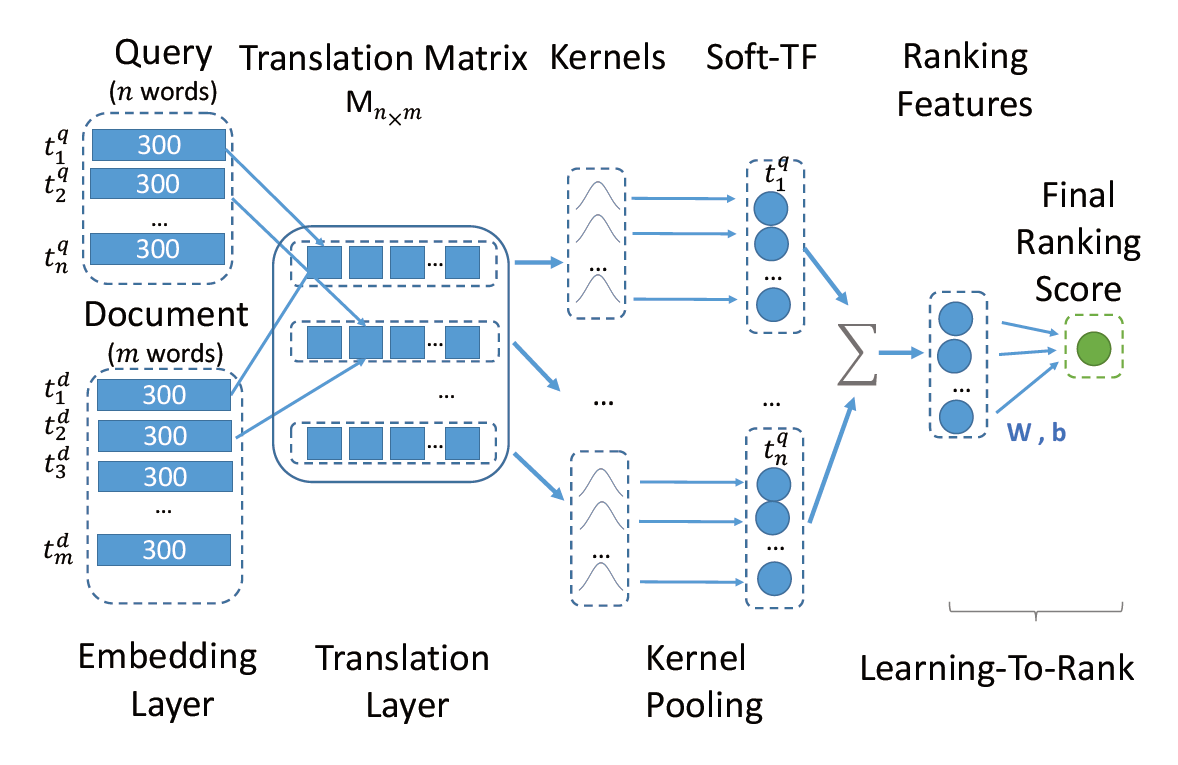
整个模型可以分为 3 层: Translation layer、Kernel pooling layer、rank layer。
Translation layer 比较简单,就是将 query 的 n 个 term 与 doc 的 m 个 term两两计算 cosine 相似度,得到 n*m 的匹配矩阵 M。
接下来是 kernel pooling 层,该层引入了 K 个 RBF kernel ,对匹配矩阵 M 中的地i行,有:
其中 和 是均值和标准差,是超参。
the RBF kernel Kk calculates how word pair similarities are distributed around it: the more word pairs with similarities closer to its mean μk , the higher its value.
这句话我没怎么理解,大意是词对相似度离均值越近,则该值越高。因此它反映了词对相似度在均值周围的分布情况。如下图所示
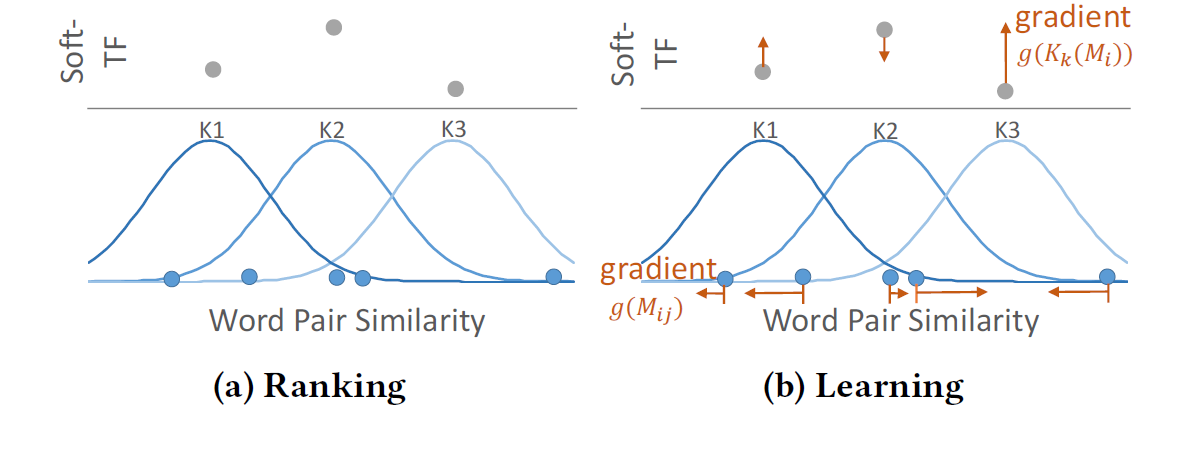
我们可以通过分析几个特殊情况看看这到底意味着什么:
- 正常情况: 越接近 u或 越接近无穷大,则输出越大
- 当方差 越接近无穷大,输出接近 1,相当于 mean pooling
- 当方差 趋近于 0,均值等于1.此时只有当 等于 1 时才能输出 1。因此相当于对 query 和 doc 中的 term 只考虑严格匹配。也就等价于 TF 词频统计模式
- 在上面情况之间的,也就可以看作是 soft-TF 模式了
每个 kernel 将输出映射为一个值,当我们有 K 个 kernel 时,每个 term 就对应一个 K 维的向量表示 。
对 n 个 term 向量进行求和得到 。最终将 输入到 FFN + softmax 中进行分类。
损失函数使用 pairwise loss,评测结果如下图所示:
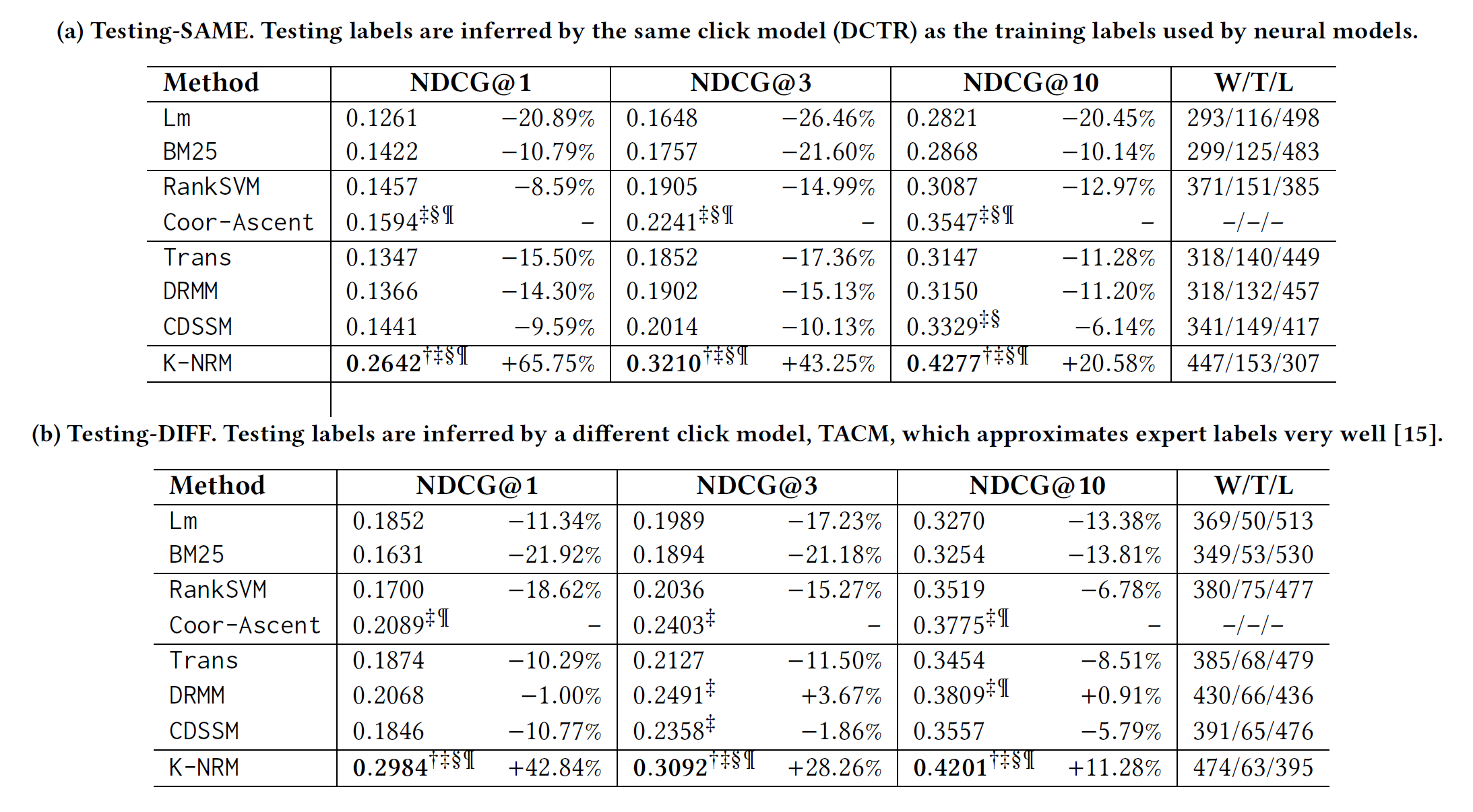
可以看出比 DRMM 要强很多。
Conv-KRNM: Convolutional Neural Networks for Soft-Matching N-Grams in Ad-hoc Search
K-NRM 直接用计算 term 间的匹配矩阵,但对于 ad hoc 检索任务而言,除了 unigram 外,使用 bigram 甚至 trigram 也是很有必要的。因此论文引入 CNN 对 query 和 doc 进行 bigram 提取。而后再计算匹配矩阵应用 kernel 什么的。
模型结构如下图所示:

整个模型可以分为 4 层: embedding 层、卷积层、cross-match 层、kernel pooling 层和 Rank 层。其实除了卷积层外其余的都差不多。
对于卷积层,采用大小为 h 的一维卷积共 F 个对 query 和 doc 进行卷积 + ReLU 操作。其中卷积核大小采用多种尺度。对于 n-gram 长度 , 包含 F 个 filter 的CNN 层将输入向量表示为:
对经过卷积层得到的表示计算匹配矩阵,设 query 的 n-gram 长度为 , doc 的 n-gram 长度为 ,则匹配矩阵中每个元素为对应 term 的 n-gram 的 cosine值:
最终得到 个匹配矩阵:
之后进入 kernel pooling 层,对 M 中的每个元素(也是一个匹配矩阵) 应用 K 个 RBF kernel ,会得到 维度的向量。
将上述向量输入到 FFN 中得到最终匹配分数。 loss 还是 pairwise loss。可以看到,主要变化就是用了不同大小的卷积核提取不同大小的 n-gram 特征,而后进行匹配得到高维的匹配矩阵,而后对高维矩阵应用 kernel ,思路还是很清晰的。
PACRR: A Position-Aware Neural IR Model for Relevance Matching
刚刚说 DDRMM 已经成功地捕捉到了unigram术语匹配,但是对于如何充分利用位置相关信息(如邻近度和术语依赖性)的研究还不够深入。,本论文通过 CNN 的卷积操作来捕捉局部词序的关系。来更好地建模位置相关的查询和文档之间的交互。
模型结构如下图所示:
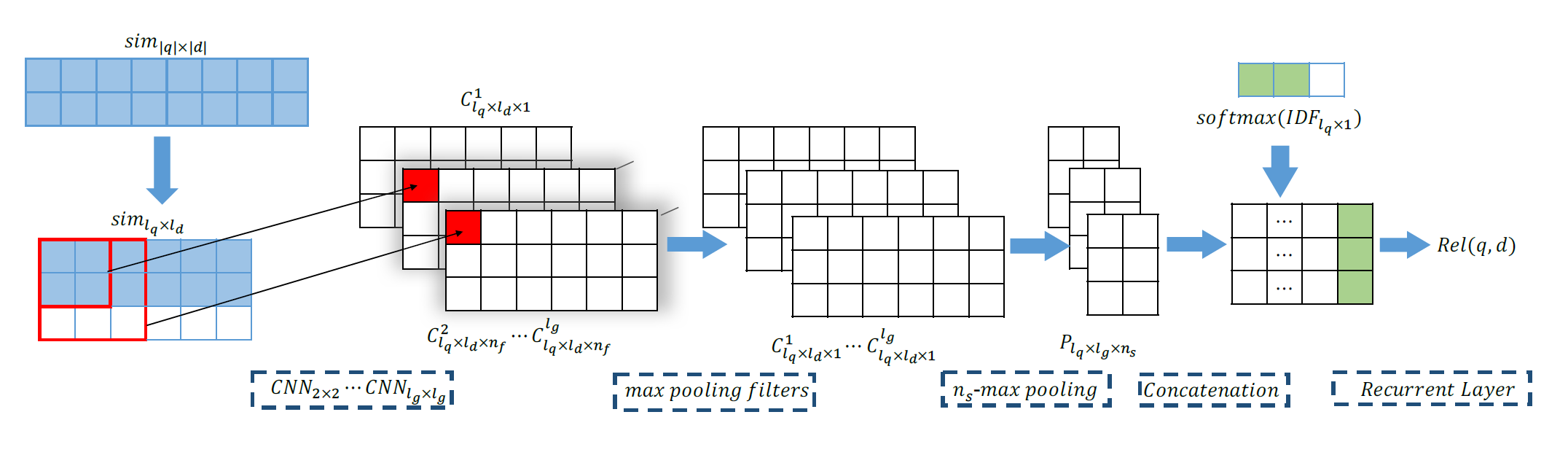
整个模型包含:输入层、匹配层、CNN 层、 pooling 层、RNN 层。输入层不用多说,就是 embedding。
对于匹配层,有两种策略:
- First-K:query 的 个 term 和 doc 的 个term 的匹配矩阵取 前 k 个 doc term 的匹配结果
- K-Window:K-Window 假设 doc 中与当前 term 匹配分较低的 term 贡献比较小。因此引入 n-gram 模型,计算 n-gram 与 query 的 term 的匹配得分:
- doc 中的 n-gram ,相当于 n 个 term, 每个 term 与 query 中的 个 term 计算相似度,取 个相似度得分中相似度分值最高的作为 该 query term 的匹配分数
- 对当前这个 n-gram 的 n 个 term 的匹配分数求均值作为该 n-gram 和 query term 的匹配分数
- 对于 doc 的所有 term 都取 n-gram ,按照上述步骤进行计算,得到该 query 对 doc 所有 term 的匹配分数向量
- 对 query 的所有 term 重复上述步骤,得到匹配矩阵,维度是
- 对所有 n-gram 匹配分数,取前 k 个
经过上述匹配,将得到维度为 的匹配矩阵。
现在将该相似度矩阵输入到 CNN 中,CNN 选用 11、22……lg*lg 得到 lg 个卷积层,来使用 unigram、bigram 等模型。 CNN 的输出维度是 ,其中 是卷积核数目。
接下来进入池化层,池化层有两个,一个是 max-pooling,对 个三维矩阵,每个矩阵 有 个 filter,通过 max-pooling 在 个 filter 中提取得到最大值。此时输出维度为 。
而后使用 k-max pooling,即在 维度上选用最大的 个,此时输出维度为 。
最后用 RNN 提取得到全局匹配信号。作者将 query 的 IDF 经过 softmax 进行归一化。而后将 矩阵进行分割(转置更合理),得到 的矩阵。相当于每个 query term 都有一个 二维矩阵。 作者再将这个二维矩阵展开成一维向量,即得到 的矩阵。最后将 个 term 的归一化 IDF concat 到末尾,得到 的向量。将该向量输入到 RNN 中对特征进行聚合来预测全局query-document相关分数。
最终实验结果如下图所示:
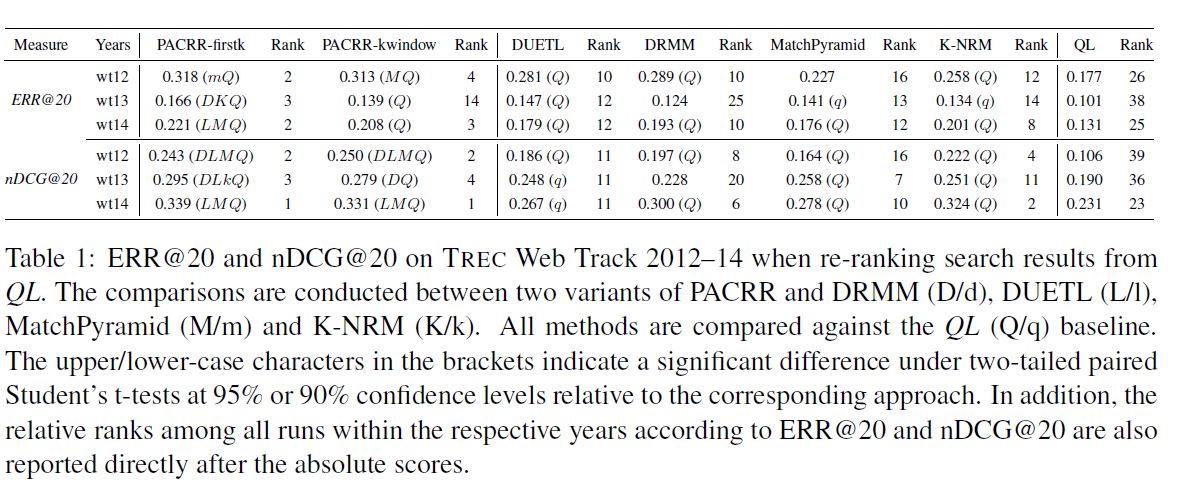
看起来 k-window 效果还没 first k 好??然后 K-NRM 比 MatchPyramid 要好? DRMM 也比 MatchPyramid好? 直方图 + FFN 都可以?难道是聚合的问题?
吸收点是:
- 对于长 doc 的处理,用 first k 效果就还不错
- 用 n-gram 信息可以通过 不同大小 kernel 的 CNN 实现
- IDF 通过 concat 在 RNN 输入前也可以有效
- RNN 用来做聚合
Co-PACRR: A Context-Aware Neural IR Model for Ad-hoc Retrieval
PACRR 虽然考虑了位置信息,但没有充分考虑上下文信息及同一文档中的其他信号,这些信号可以帮助提升整体的相关性得分。因此该论文提出:引入上下文信息、级联 k-max pooling 和 query 位置随机打乱来解决上述缺点,得到新模型 Co - PACRR。
模型结构如下图所示:
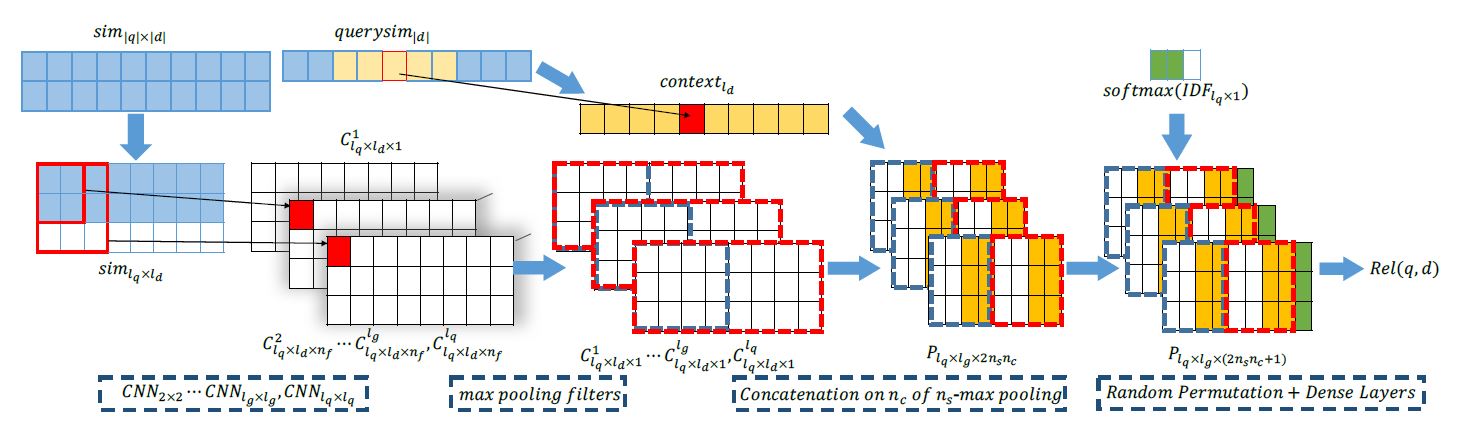
整体上还是遵循 PACRR 结构的,下面着重说一下不同点:
-
引入上下文信息:在输入层,除了原始 term 间的匹配矩阵外,还考虑当前 term 上下文和 query 的相似度。具体来说,对于 query 的上下文我们采用整个 query 的所有 term 向量取 平均得到上下文表示 。但对于 doc,由于 doc 文本比较长,因此取窗口大小为 的上下文内取平均得到 doc 第 i 个term 的上下文表示 。 最终上下文相似度:。
-
级联的 k-max pooling:PACRR 中 k-max pooling 只要前 k 个,但这里引入新的超参数 ,表示将 整个 doc 划分为 分,之后对每份内取前 k 个得到 个值。
-
query 位置的随机打乱: 对于短的 query 会在尾部用 0 进行 padding ,这会让模型认为尾部信息不重要,这与实际情况不符,因此将矩阵的行进行随机打乱,使得零填充的部分分散在各处。
实验结果如下图所示:

总结
看完上面的论文, 大体总结出一个框架, 分为 输入、再编码、交互匹配、聚合、输出 四个部分。
- 输入:除了 DSSM 等一开始用 word hashing 外, 基本上用的都是 word2vec 和 Glove 的各种向量嵌入方法,不过对于 IR 领域词典大的问题, 可以选择适合的方法
- 再编码:可选的一部分, 前期像DSSM 一类的没有用, 但后面很多工作用了,可选的方式为 self-attention(以及其他自对齐的方法)、BiLSTM, CNN,目的是获取句子内部的前后文语义信息
- 交互匹配: 基于表示的模型没用这步, 但这基本上都是早期的工作, 今年的工作基本上都考虑了交互匹配这步, 可选的方式如: cros-attention, 通过 cosine/ dot/ indicator/ 欧几里得距离 等构造的匹配矩阵、元素级别的点乘和相减等。
- 聚合: 交互匹配得到的通常是维度比较高的矩阵, 因此需要采用一定的方式进行降维,得到定长的低维向量表示, 可选方式为: 池化(最大池化,均值池化, 加和等)、线性+激活函数、CNN、BiLSTM 等方式
- 输出: 有了定长的向量表示后, 可以采用 cosine 和 FN + softmax 等方式计算相似度
以上就是个人总结出来的框架。
关键词
- Question Answering
- Relevance Matching
- Semantic Matching
- Answer Selection
- Matching Network
- Natural Language Inference
- Text Matching
- Modeling Sentence Pairs
- Matching Model
- IR Model
- Sentence Similarity
- Semantic Similarity
- ranking
- Response Selection
TODO
- Transformer 在 文本匹配中的应用
- 预训练时代的文本匹配